


近几年流露器厂商的价钱战愈演愈烈,2K以及4K高清流露器的普及率激增,2k@240Hz或者4K@120Hz的电竞流露器早已走到平常玩家的电脑桌上。
保险2K分辨率下的游戏开通度成为本年中高端显卡的必修任务,我们今天要测评的对象是影驰 GeForce RTX 5070 魔刃 OC 12GB(以下简称为影驰 RTX 5070 魔刃 OC),这是英伟达本年中高端的代表作,这张卡较着承载着英伟达新一代显卡若何安靖地开通玩转高分辨率游戏性能的叙事,事不宜迟接下来飞快望望这张显卡的规格特质吧。

GeForce RTX 5070规格一览
GeForce RTX 5070基于Blackwell架构,由TSMC 4N NVIDIA 定制工艺打造。Blackwell架构搭载了第4代RT Core以选取5代Tensor Core,其CUDA规模达到了6144组。行动OC后缀的非公版,影驰 RTX 5070 魔刃 OC的频率理所自然比公版更高,其基础频率为2325MHz,加快频率来到了2557MHz,而基础TGP功率则与公版持平为250W,MAX工况可达300W。GDDR7是新一代N卡的亮点,该卡配备了频率为28Gbps,容量达12GB的192-bit GDDR7内存,显存带宽高达672GB/s。
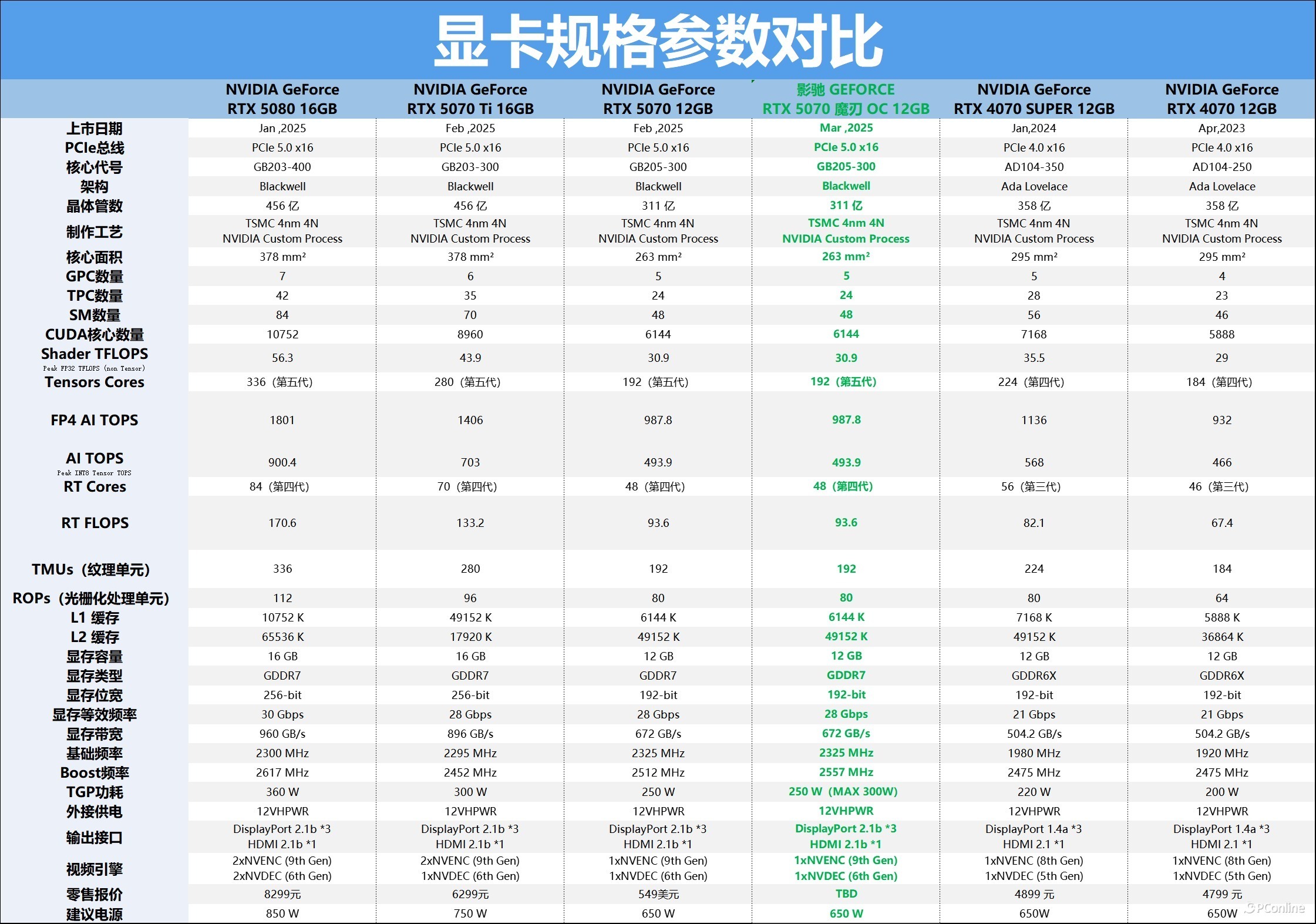
检讨规格参数表的话会发现一个很兴味的惬心,RTX 5070与RTX 5070 Ti之间收支22组SM单位,是当前依然公布的RTX 50家眷中规模最小的中枢。与此对应的是,此次NV对RTX 5070的官方零卖价也作念了扶助,RTX 4070的发售价是4799元起,而RTX 5070的发售价则来到了4599元起,OC版则是各厂商纯真订价,价钱更亲民且性能比RTX 4070更强,加量还减价了属于是。不外如故那句话,当前RTX 50系新品市集价比较紊乱,以上提到的仅为表面参考。
游戏性能测试
纸面数据点到即止,接下来我们直奔主题,望望影驰 RTX 5070 魔刃 OC的游戏推崇。运行共享数据前先先容一下我们的测试平台配置:我们摄取了现代游戏神U——AMD锐龙7 9800X3D,与之搭配的主板是微星高端主板MSI MPG X870E CARBON Wi-Fi,以及芝奇T-FORCE XRTEEM ARGB 幻镜 DDR5-8000 C38 24GB*2,这套平台的性能理当能将影驰 RTX 5070 魔刃 OC的游戏性能完全瓦解出来。

先望望基础的游戏性能,我们测试了《光明牵记:无穷》《古墓丽影:阴影》《干戈机器5》等13款游戏,并比较影驰 RTX 5070 魔刃 OC与RTX 4070在2k分辨率下最高/极致画质确立下的平均帧互异。
在不借助DLSS 4的状态下,实测影驰 RTX 5070 魔刃 OC比RTX 4070强12%~48%,平均强29%,除了《黑传说:悟空》《星球大战:法外狂徒》《鸣潮》等对硬件条件非常高的游戏,大部分游戏的平均帧率王人在100FPS以上,极个别优化得非常好的,比如《极限竞速:地平线5》的平均帧致使飙到255 FPS。

以超高负载的新一代硬件杀手《黑传说:悟空》为例,2K分辨率影视级画质确立下,RTX 4070依然难以将平均帧守护在60FPS以上,而影驰 RTX 5070 魔刃 OC的平均帧达到了69FPS,这就意味着大多数场景下,游戏的开通度是有保险的。我们测试的13款游戏里面只好《黑传说:悟空》出现了这个气象,但跟着UE5引擎的游戏渐渐普及,难保以后这类“60FPS分水岭”式的气象会在这两张卡身上经常献技。
好了,接着我们望望搬出RTX 50系大招——DLSS 4的情况,在之前的测试中我们早就眼力过DLSS 4多帧生成时间的苍劲魔力,当前这股帧率狂飙的“爽劲儿”连续到影驰 RTX 5070 魔刃 OC。
参与此次两代显卡对比的游戏为《赛博一又克2077》《星球大战:法外狂徒》《霍格沃兹之遗》以及《漫威争锋》,这4款游戏当前依然维持DLSS 4,从表格数据不难发现,在多帧生成加持下,影驰 RTX 5070 魔刃 OC的游戏性能大幅最初RTX 4070,平均最初幅度高达110%。
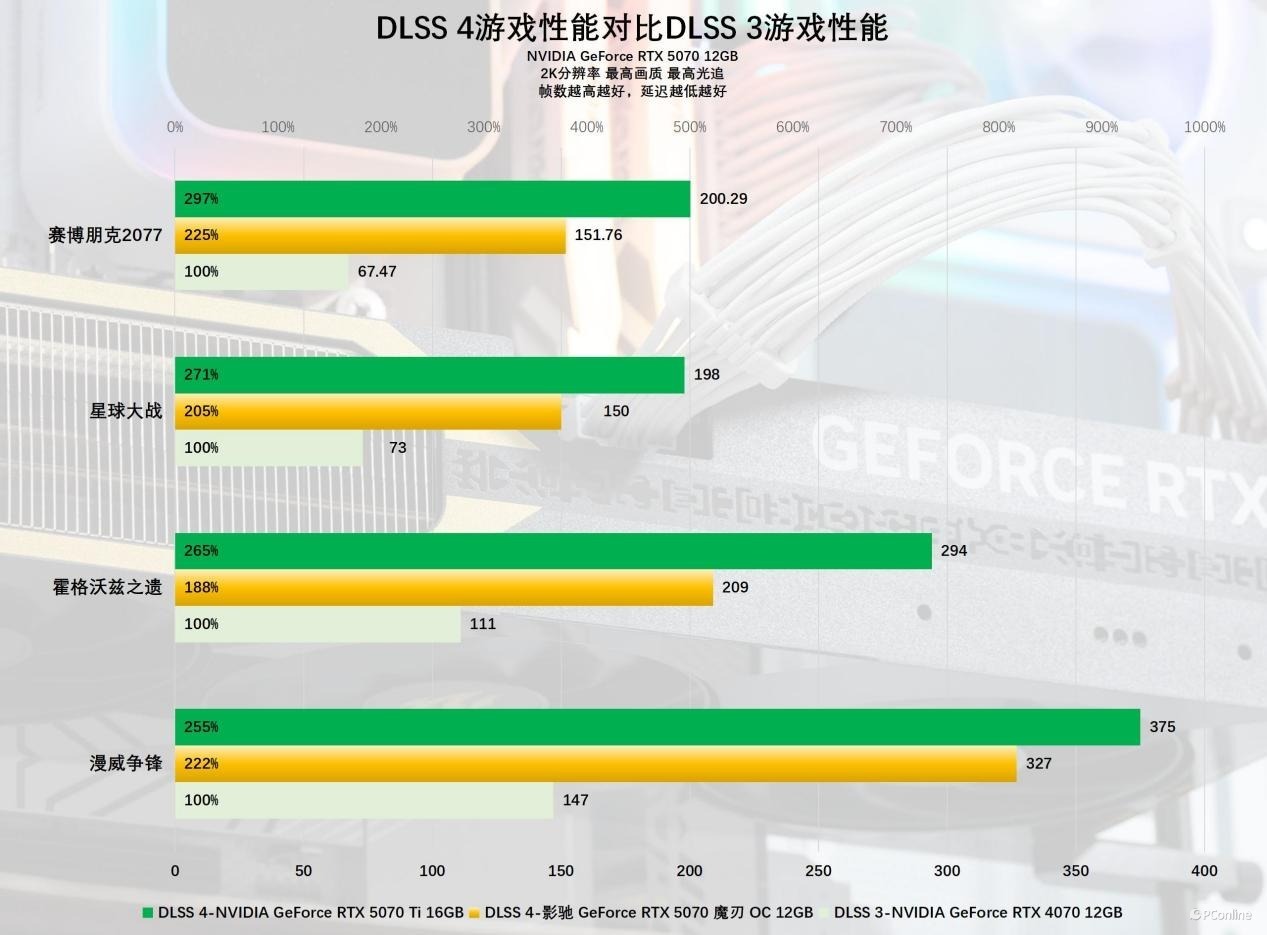
底下我们再翔实探讨DLSS 4时间对影驰 RTX 5070 魔刃 OC的加成幅度若何,我们对比了该卡在【关闭DLSS】、【DLSS 4帧生成2X】、【DLSS 4帧生成4X】三项确立的帧率变化,测试的游戏相通是刚提到的4款已维持DLSS 4游戏。
实测拔除十分夸张,开启【DLSS 4帧生成4X】后,4款游戏的平均帧率毫无疑问王人在暴涨,《赛博一又克2077》平均帧率暴涨543%、《星球大战:法外狂徒》平均帧暴涨456%,其他两款游戏的平均帧也暴涨了200%以上,帧率训诫十分显耀。
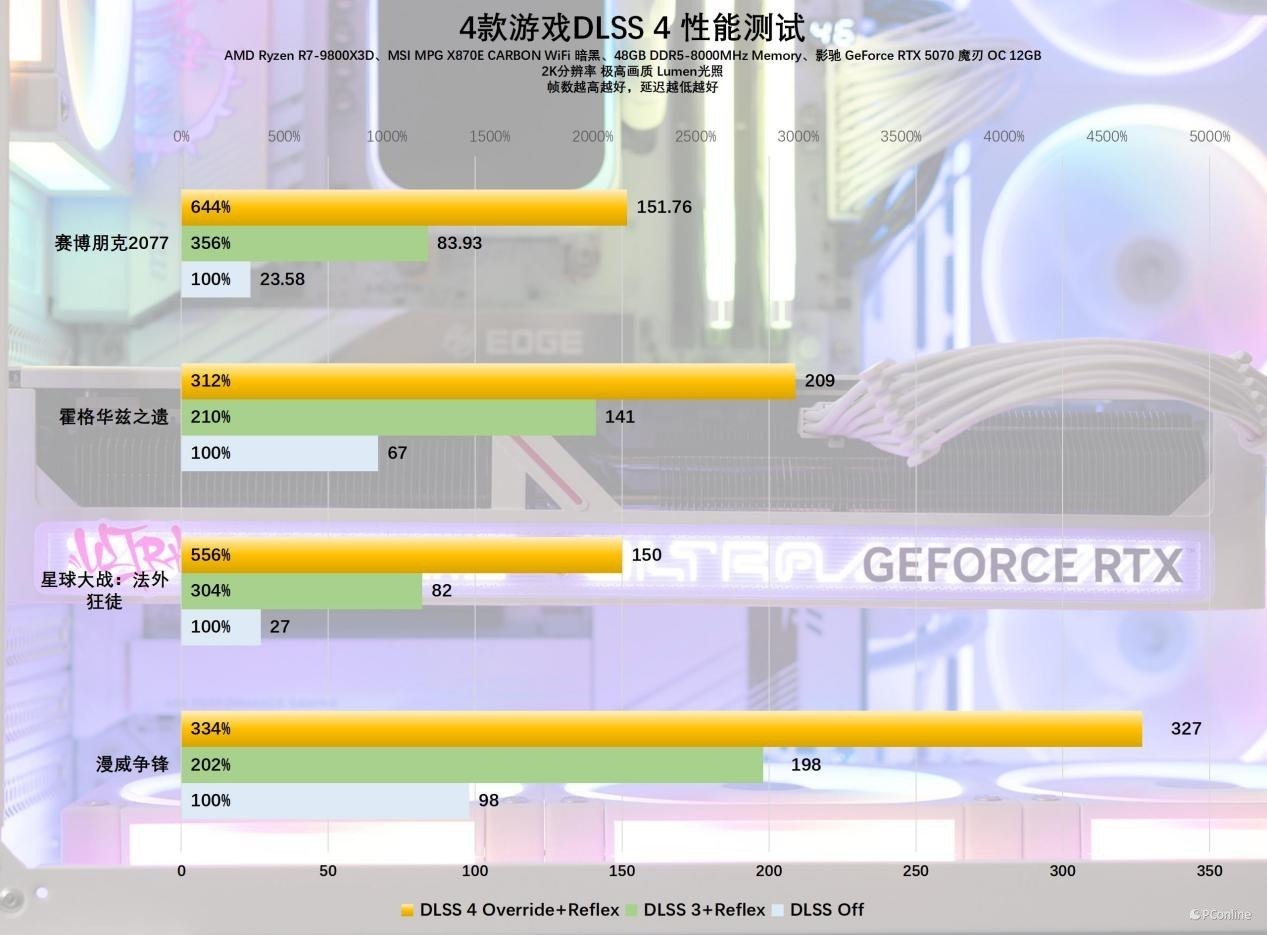
具体到当前维持DLSS 4的3A大作,先是率先引入了旅途跟踪的《赛博一又克2077》,这款游戏负载之变态较早前看过我们测试的小伙伴应该王人清亮,上个月RTX 50系的首测依然讲授了,只要有DLSS 4 多帧生成时间的加持,RTX 50系王人能简陋拿抓这款硬件杀手。在2K分辨率下没开DLSS 4之前,影驰 RTX 5070 魔刃 OC的平均帧只好23.58 FPS,这帧率依然难以说得上开通了。开启DLSS 4后平均帧暴涨至152 FPS,简陋玩转硬件杀手。
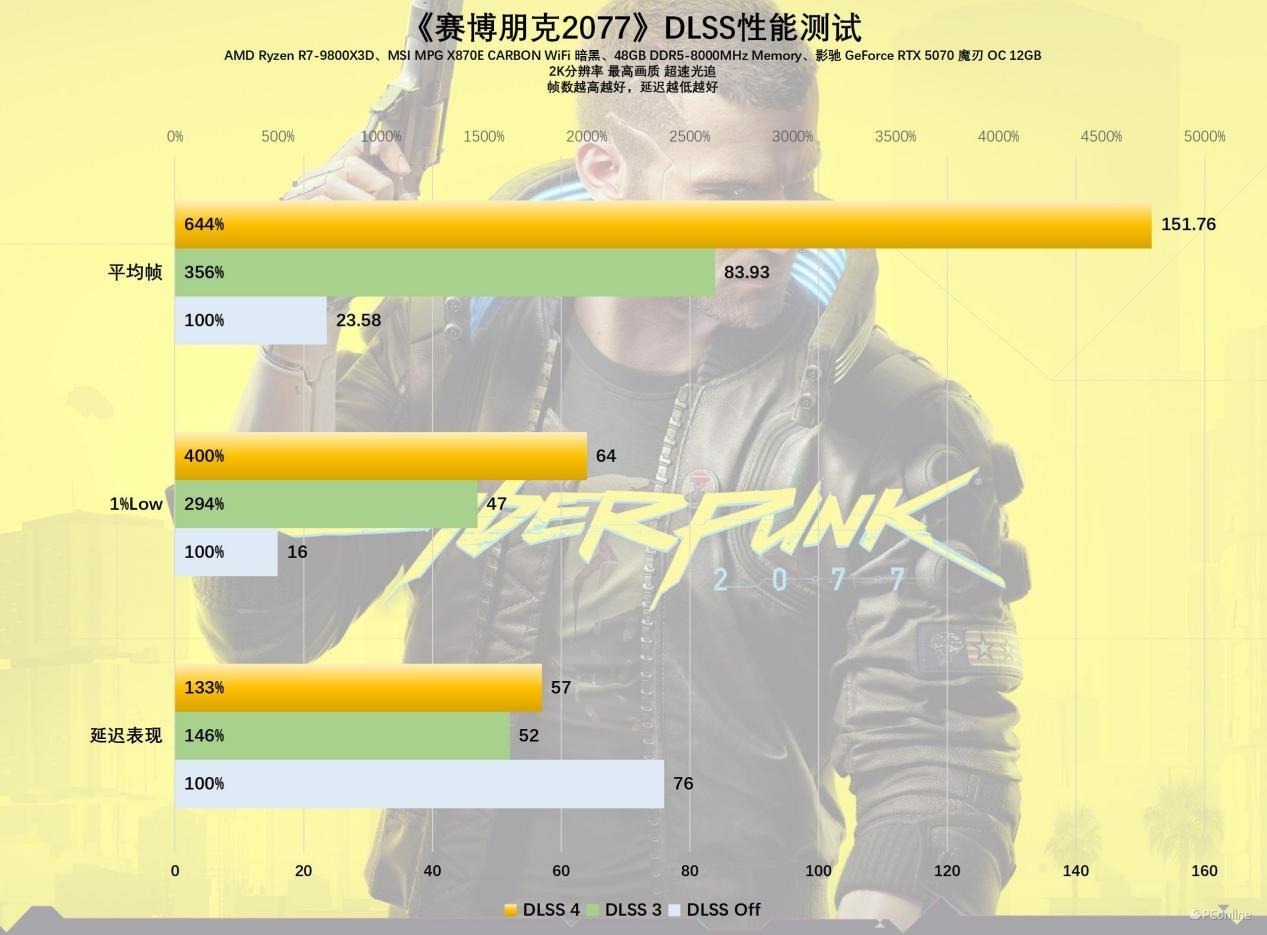
再望望硬件条件相对较低的《霍格沃兹之遗》,在不开启DLSS时,影驰 RTX 5070 魔刃 OC的平均帧仅为67 FPS,对付开通玩的进度,开启DLSS 4后,平均帧率龙套了200 FPS大关,1%帧暴涨至92 FPS,从对付开通玩一下子变成喂饱144Hz高刷屏,游戏体验杀青了跃升。
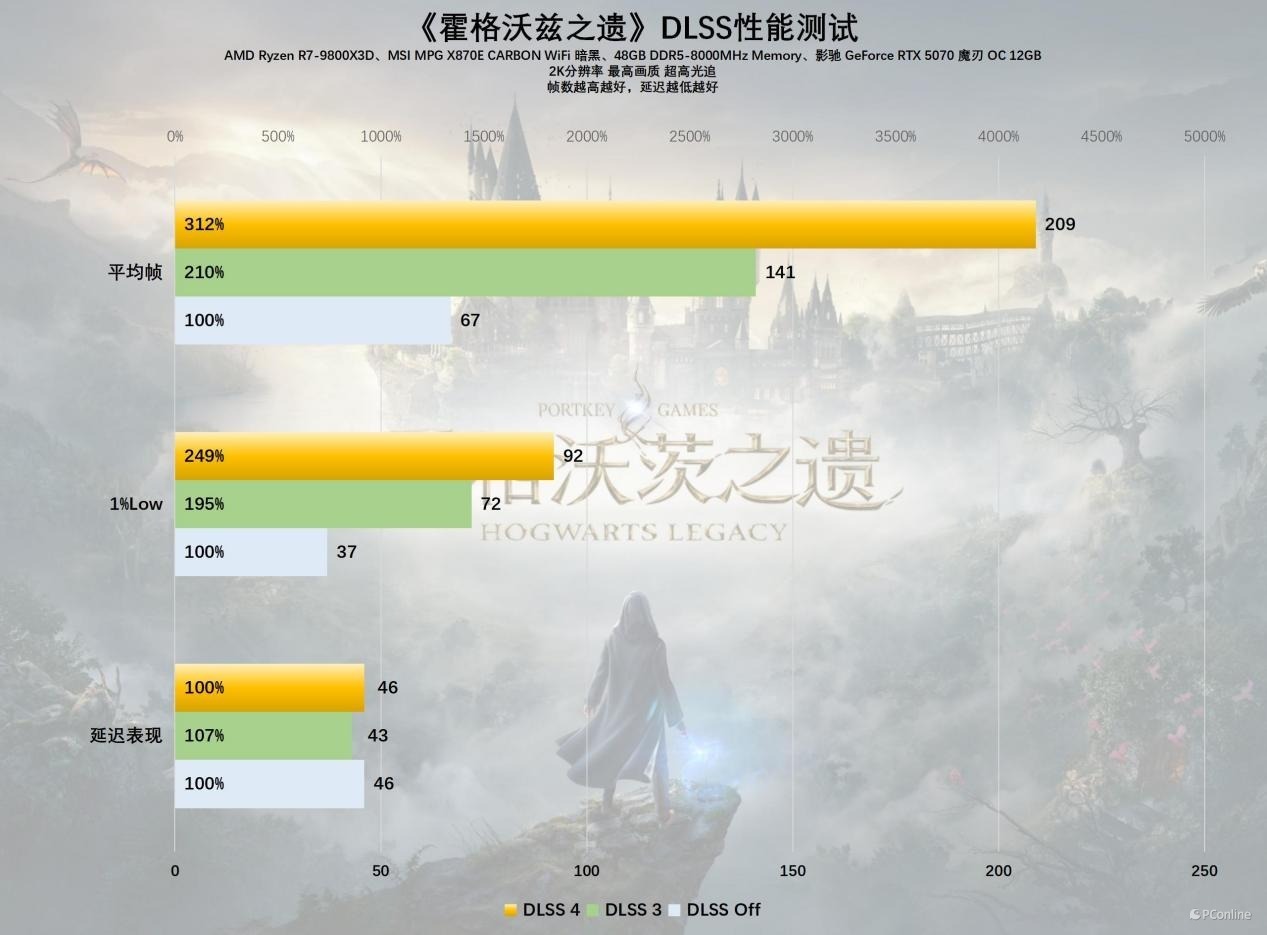
接着是《星球大战:法外狂徒》,这相通是一款硬件杀手,在2K分辨率DLSS OFF时,27 FPS的平均帧以及24 FPS的1%LOW帧依然属于无法游玩的状态,而DLSS 4再次施展魔力,将平均帧率拉到151 FPS,这帧率的训诫幅度实在太奇幻了,即便在之前的测试中我们依然屡次领教过,但如故以为不行想议。
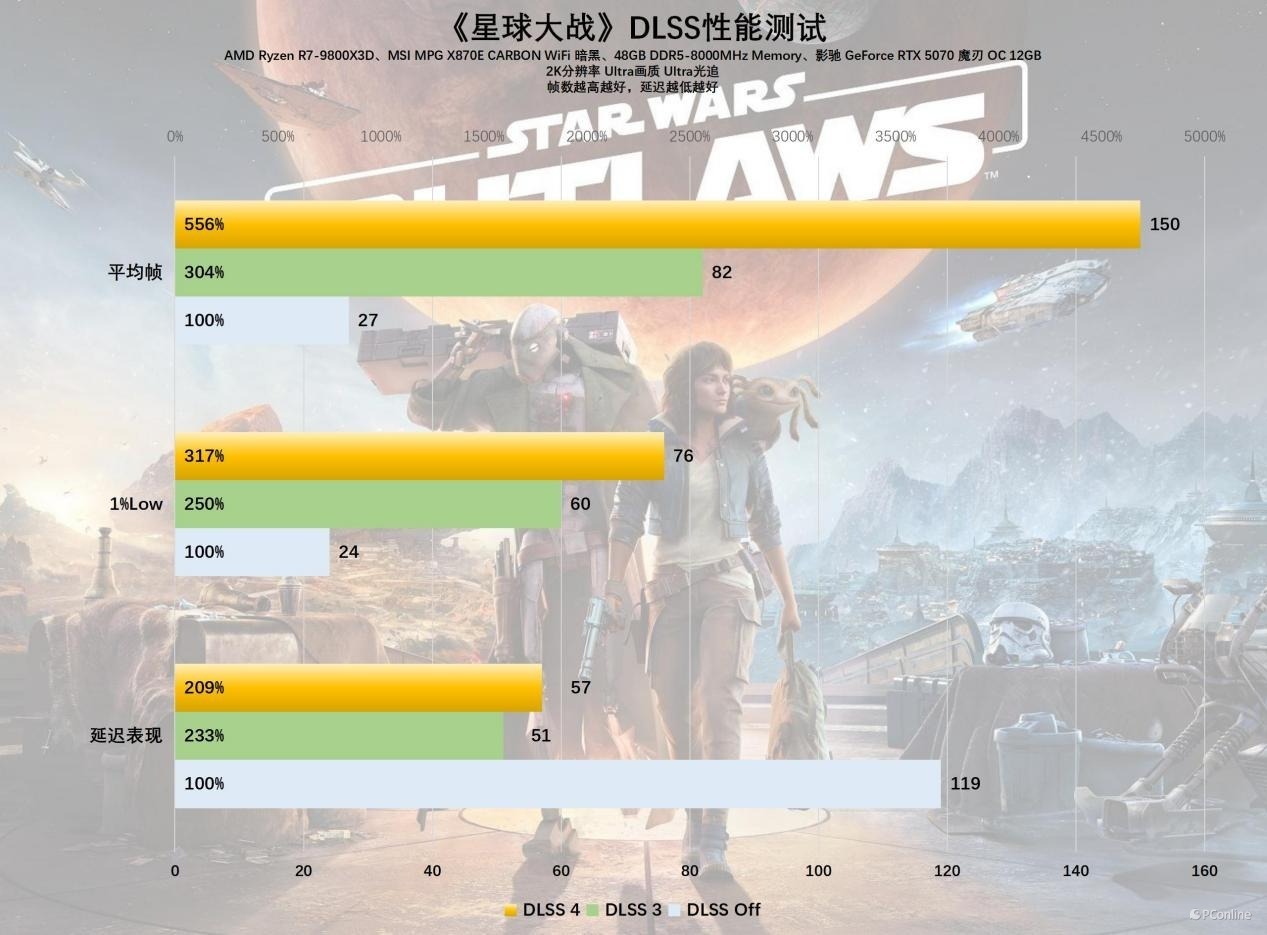
终末是喜闻乐道的《漫威争锋》,这是一款竞技类网游,游戏的受众对帧率的自然条件极高,但游戏开发商又偏巧给这款游戏加入光追等对帧率影响十分较着的画面确立,导致这款游戏成为网游界的显卡杀手。在2K分辨率DLSS OFF时,影驰 RTX 5070 魔刃 OC的1%LOW帧仅有77 FPS,平均帧率98 FPS,这帧率推崇较着很难让玩家感到安逸。好在当前有了DLSS 4,开启后平均帧率巧诈到327FPS,1% LOW帧也有225FPS,这个成绩全王人能让画质党安逸。
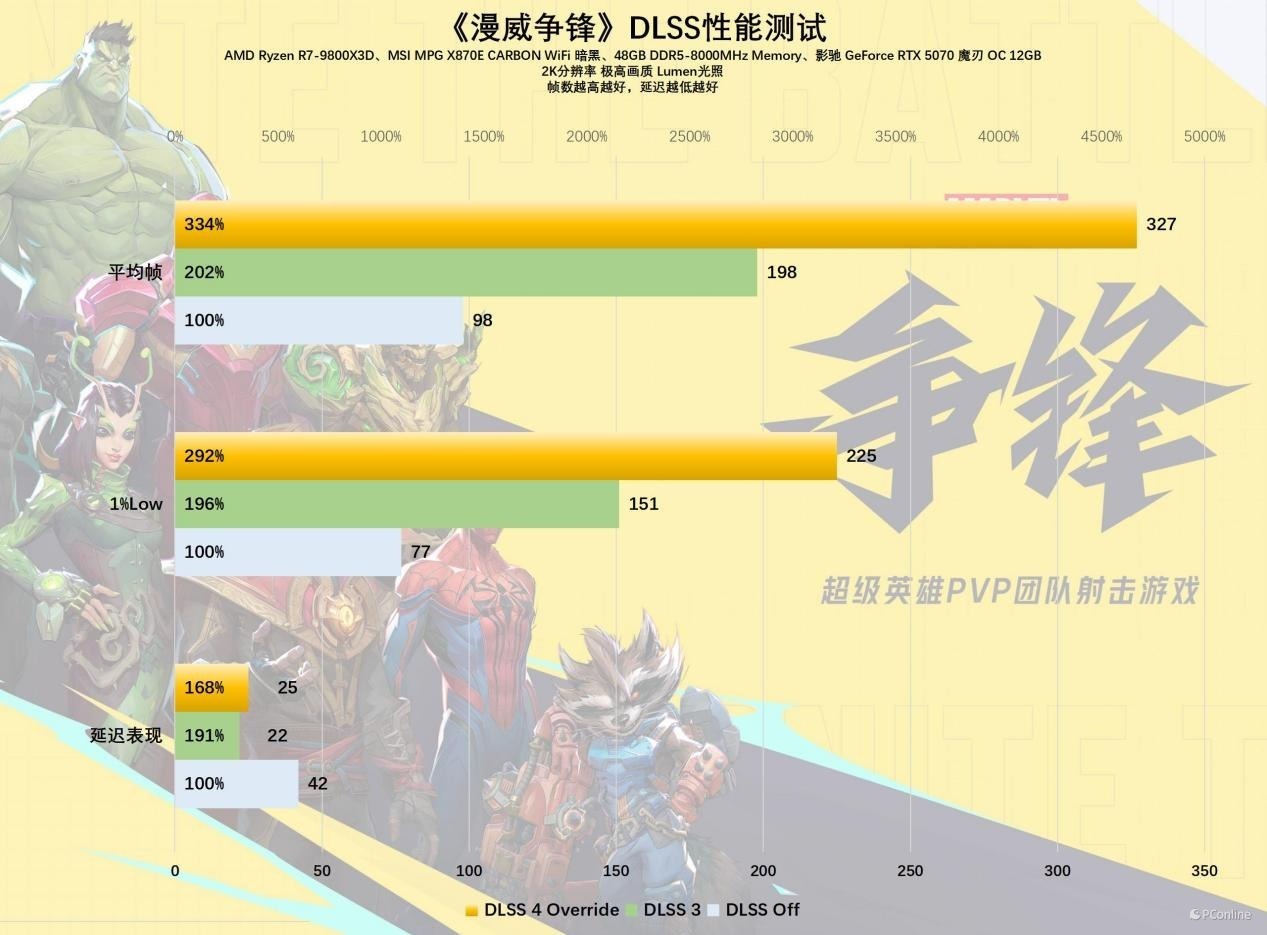
看完4款游戏的推崇我们可以先下论断,DLSS 4时间关于显卡的训诫十分较着,即即是12GB显存的影驰 RTX 5070 魔刃 OC,其依然具备优秀的游戏性能,2K分辨率下的高画质开通体验依然达标,畴昔跟着搭载DLSS 4的游戏越来越多,RTX 50系显卡的游戏性能上风还会愈发较着。
外不雅篇:魔刃潜能 蓄势待发
说完游戏性能再看回测试显卡自己,影驰 RTX 5070 魔刃 OC的包装连续了RTX 5080、5070 Ti魔刃的作风,金色的魔刃图案取自“刃BLADE”主题,大面积的玄色主调与显卡的外不雅彼此呼应。

终止包装就能见到显卡的本质,包装内还附赠了一个显卡支架、一根灯光限制线以及一个2x8 Pin转12V-2x6转接线,细节配件计议得十分玉成。

将显卡的贴膜撕掉后就能看到影驰 RTX 5070 魔刃 OC的完整外貌了。

险些全黑的散热器外壳里,位于电扇中央的刃型图标十分吸睛,黑金激情遐想也彰显了高等感。

散热器外壳的光面与磨砂面斜纹相间,这种遐想理念常用来抒发动感,配上立体感十足的霜环扇叶,营造出芒刃行将出鞘的氛围。

这代霜环散热器的三个霜环扇叶的尺寸为90mm,颇具特色的三折遐想以及7叶结构在同杂音下风压训诫15%,同转速下杂音镌汰5%,风压训诫10%,同期扇叶的全体强度还训诫了。

细节处可见“刃BLADE”符文,细看的话会发现这些符文围绕着显卡一圈,影驰将其称为符文环绕后果。

翻到背面就能看到符文的另一段了,背板上还有“刃BLADE”的图案,全体的视觉后果十分丰润。

背板结尾是经典的镂空遐想,因为该卡的8层PCB遐想得比较紧凑,并未占据三电扇的长度,这么的镂空遐想能尽可能地训诫散热模组的散热效率。

显卡的侧边相通围绕着一圈符文,在顶部的位置能看到几个金属触点,其实这是影驰预留给磁吸式GALAX Aurora RGB信仰Logo的通电接口。

显卡的尾部相通预留了磁吸式接口,用户可以在两个位置中选一个放弃磁吸式RGB LOGO配件。

12V-2x6供电接口摄取了反扣式遐想,相宜ATX 3.1与PCIE CEM 5.1程序,这亦然RTX 50系列显卡的主流形态,供电接口旁还有一个灯光同步接口。

显卡的顶部并非完全禁闭,影驰在供电接口旁留了一段镂空,便捷散热器交换空气。

顶部跟底部PCB面的镂空大致上是对称的,这也意味着显卡侧面的符文图腾环绕了三个面,一直延迟到镂空处为止。

影驰 RTX 5070 魔刃 OC提供了3个DP 2.1b以及1个HDMI 2.1b,一共四个流露输出接口,从IO端口这边可以看出该卡的厚度略高于双槽。影驰宣称这相宜英伟达的SFF-Ready程序,意味着这个卡对机箱的兼容性会比较友好。

接着我们再望望上机的状态,前边提到的磁吸式配件能兼容横装和竖装两种形态,RGB灯效也把情谊价值提供到位。

搭配上影驰随卡附赠的显卡支架,整机的造型作风将会十分斡旋,有了这个支架复古,用户就可以简易地在显卡上放弃手办啦。

我们模拟日常不雅看显卡的视觉,“刃BLADE”符文的环绕式布局给显卡营造出魔力缠绕的视觉后果,这个工整想很兴味。

拆解:
接下来我们终止显卡望望里面的构造和芯片真容吧,想了解翔实跑分的小伙伴可以下拉到后头的章节。
拆卸显卡的要领是相对肤浅的,开始卸下背板的螺丝将背板取出,接着卸下IO面板的螺丝以及X型框架螺丝,将PCB与散热鳍片分离(属目散热器与PCB连线),终末卸下金属中框螺丝取出中框,至此显卡的背板、合金压铸中框、PCB、散热器外框、散热鳍片这五个部分就算分离完成。

影驰 RTX 5070 魔刃 OC的元器件规整斡旋,相宜影驰一贯以来的作念工。显卡的供电规格为10+3相,完全相宜250W显卡的使用工况。

可以看到这张显卡的GPU中枢代号为GB205-300-A1。

显存来自三星的GDDR7,丝印为K4VAF3257ZC-SC28,显存位宽192bit,显存带宽为672GB/s,一颗显存的容量为2GB,一共6颗显存IC组成12GB显存。

可以看到围绕中枢的显存焊盘有8个,其中有2个位置被空置。

中枢MOSFET以及显存MOSFET的IC型号均为SiC658A-8448LM。

PCB的背面有一枚uS5650Q芯片,这是一个四通谈的模拟预滤波器和多路复用器。

散热器的电扇供电等接口被安排在PCB的边际位置,便捷安设和拆解。

中枢供电接口和灯光限制接口则安排在PCB顶部边际位置。

看完PCB部分再望望散热鳍片,散热器与GPU的构兵面为均热板遐想,散热鳍片与导热管均经过镀镍处理,耐用性更好。

供电部分以及显存部分平分派了导热垫,4根6mm复合热管搭配回流焊工艺可以将热量快速扩散到散热鳍片,进而将热量快速排走。

总体看下来,影驰的作念工及用料可以,合金压铸中框奉命了历代魔刃的遐想话语,可以灵验地加强显卡全体强度,加上显卡附赠的支架,这套组合拳下来,想必能完全幸免显卡变形或者PCIE接口被压坏等问题。

XTREME TUNER软件:极客玩具
显卡的配套软件早已成为AIC大厂基本功,影驰提供的显卡配套软件是XTREME TUNER,这是一款鸠合了监控显卡状态、超频显卡以及限制电扇转速等功能的使用软件。

仿跑车样貌盘的UI十分讨喜,通过软件监控显卡的参数时真有一丝开车的嗅觉。同期,软件的主邀功能王人鸠合在吞并页面,基本莫得上手难度。这个软件能平直限制显卡的中枢电压、GPU功率显存功率以及电源阈值等参数,给心爱折腾显卡的极客玩家提供了不少便利。

对参数不熟悉又想尝鲜超频的小白玩家可以遴选一键超频,这个选项可以匡助普通玩家快速地白嫖到一丝极度性能。

RGB灯光是当前电脑硬件的主流遐想,XTREME TUNER预设了3种灯光模式,灯光控也可以自行微调灯光的激情、责任模式等。

以为影驰官方的散热计谋太保守或者太激进的小伙伴,也可以通过这个软件平直定制显卡电扇的责任弧线,让显卡的散热模式真果真正地相宜使用者的真实使用环境。
基准性能测试——表面性能测试
显卡的基本情况共享罢了,接下来就是性能实测要道,为了更好地呈现影驰 RTX 5070 魔刃 OC的性能定位,我们把RTX 4070以及RTX 5070 Ti的性能也拉过来通盘对比。先望望表面性能若何,我们主要参考3DMark基准。在Fire Strike Ultra的基准测试中,影驰 RTX 5070 魔刃 OC的性能大要是RTX 4070的141%;到了DX12的Time Spy测试中,前者性能是后者的128%;在对显卡压力最高的Speed Way基准中,新卡最初幅度又回到了31%。
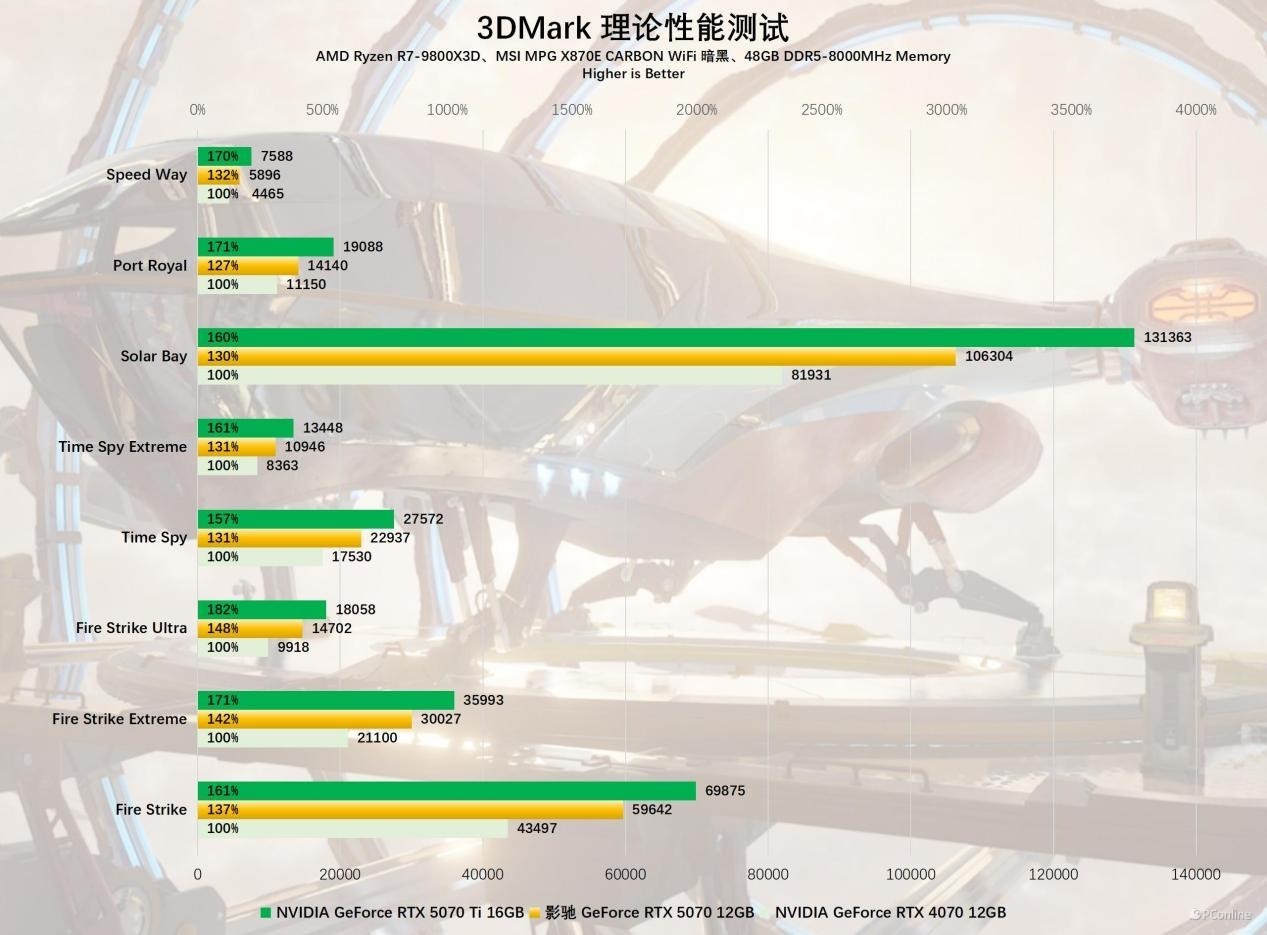
3DMark还提供了DLSS 3测试,新老两代显卡的性能互异在各项负载下王人比较平均,影驰 RTX 5070 魔刃 OC最初RTX 4070 30%支配。
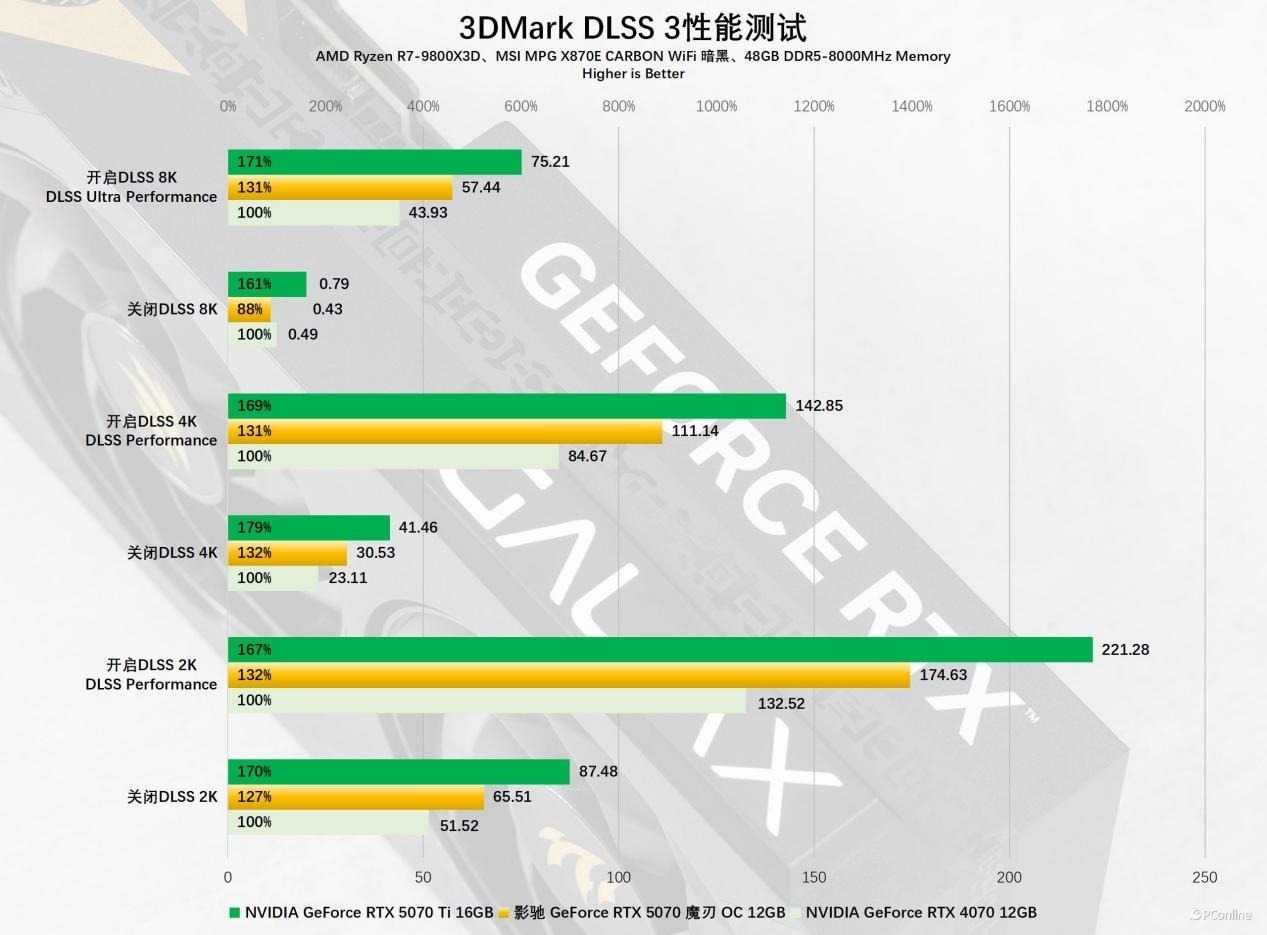
此外3DMark早已加入了DLSS 4的对比测试内容,实测DLSS 4所带来的训诫十分较着,4K分辨率下,DLSS 4相对DLSS 3的帧率暴涨,即便在超高负载的8K样例里,影驰 RTX 5070 魔刃 OC仍然跑出了105.02 FPS的成绩,帧率比拟DLSS3训诫了83%,中高端显卡也能开通运行如斯超高负载的样例,这就是DLSS 4魔力时刻。
基准性能测试——AI性能测试
聊完表面性能,我们再来聊时下大热的AI基准。这代新品的其中一个紧要更新就是原生维持FP4精度模子,凭据英伟达的官方说法,有了这项新本性,RTX 50系比拟RTX 40系的效率更高,显存占用还更低了,想了解细则的小伙伴可以下拉到文末时间默契。
FLUX.1 AI Image Generation Demo For NVIDIA就是一个现成的能考据FP4精度的基准,实测拔除好意思满展示了FP4的魔力,RTX 4070需要快要1分钟才能生成一张图,而影驰 RTX 5070 魔刃 OC仅需13秒,诚然性能略逊于RTX 5070 Ti,但代际训诫依然非常较着,这项对比也充分展示了原生FP4的高效率优点。
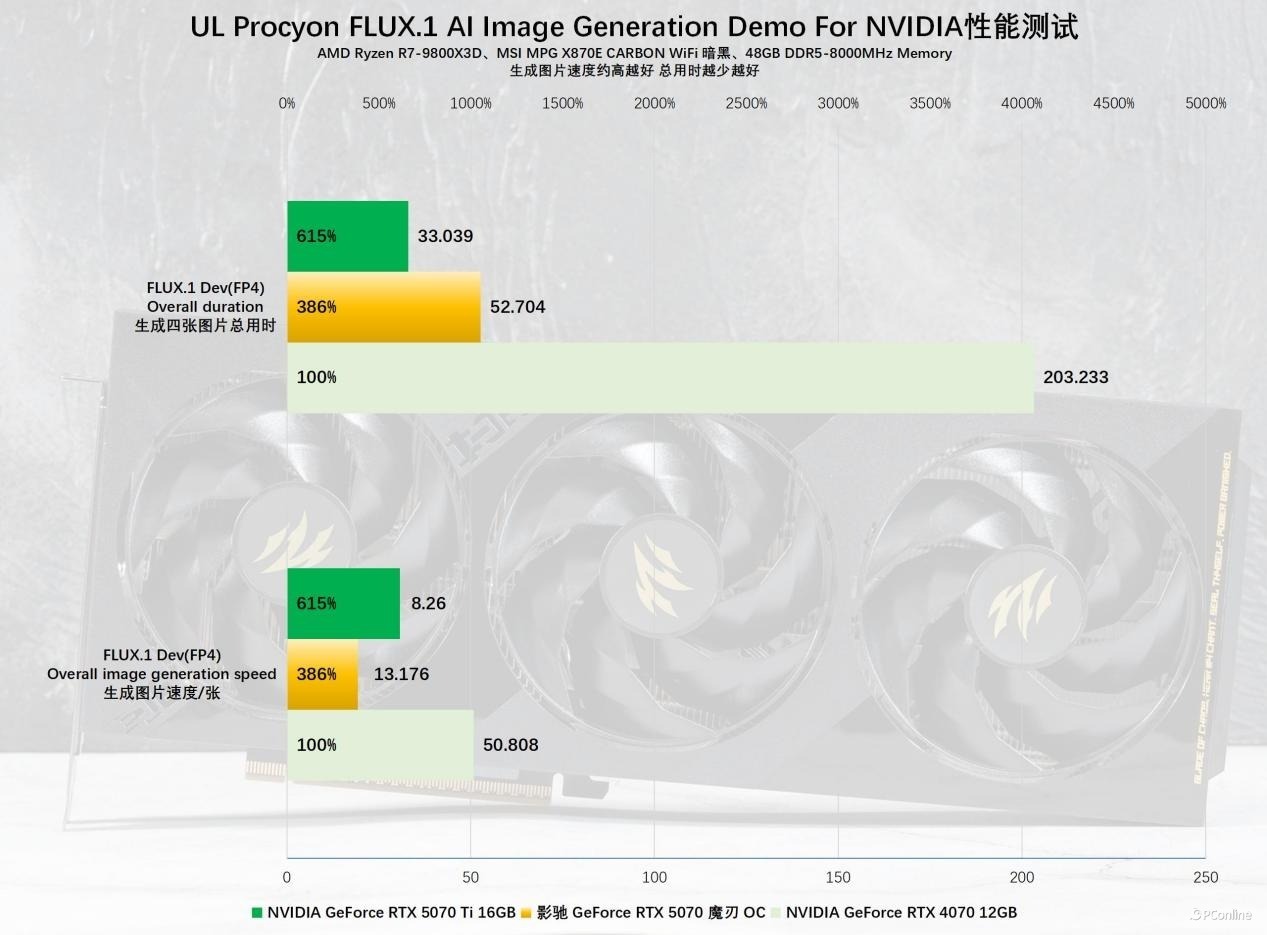
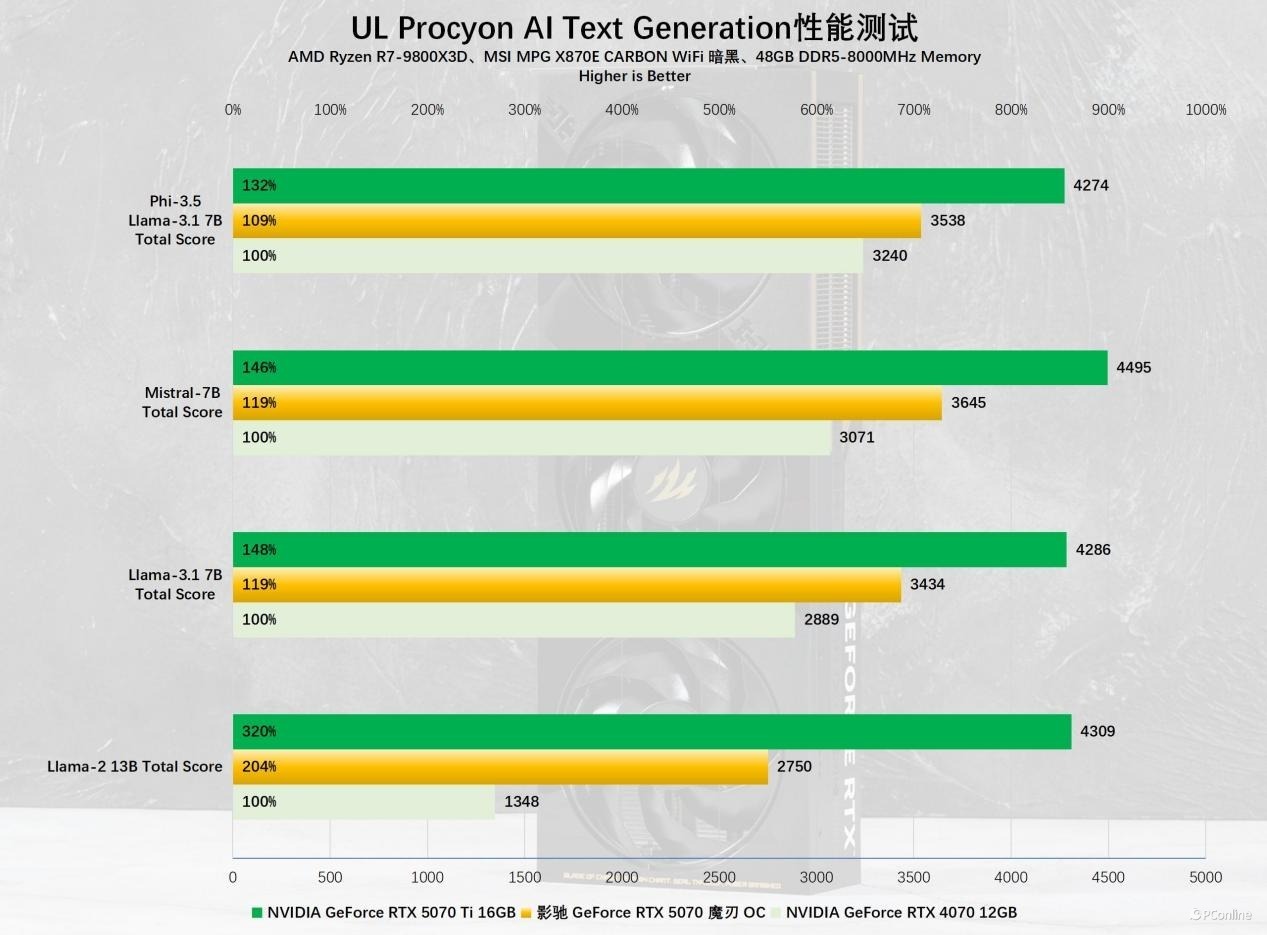
再来看空话语模子鸠合基准——AI Text Generation Benchmark,我们以PHI 3.5、LLAMA 3.1、Llama 2、Llama 3.1的得分行动参考基准。从实测拔除来看,影驰 RTX 5070 魔刃 OC的推崇可圈可点,对比RTX 4070的最初幅度在9%~104%之间,尽管不同模子下新老两代卡的代际互异各不相通,但能看出来新卡的AI性能依旧较着。
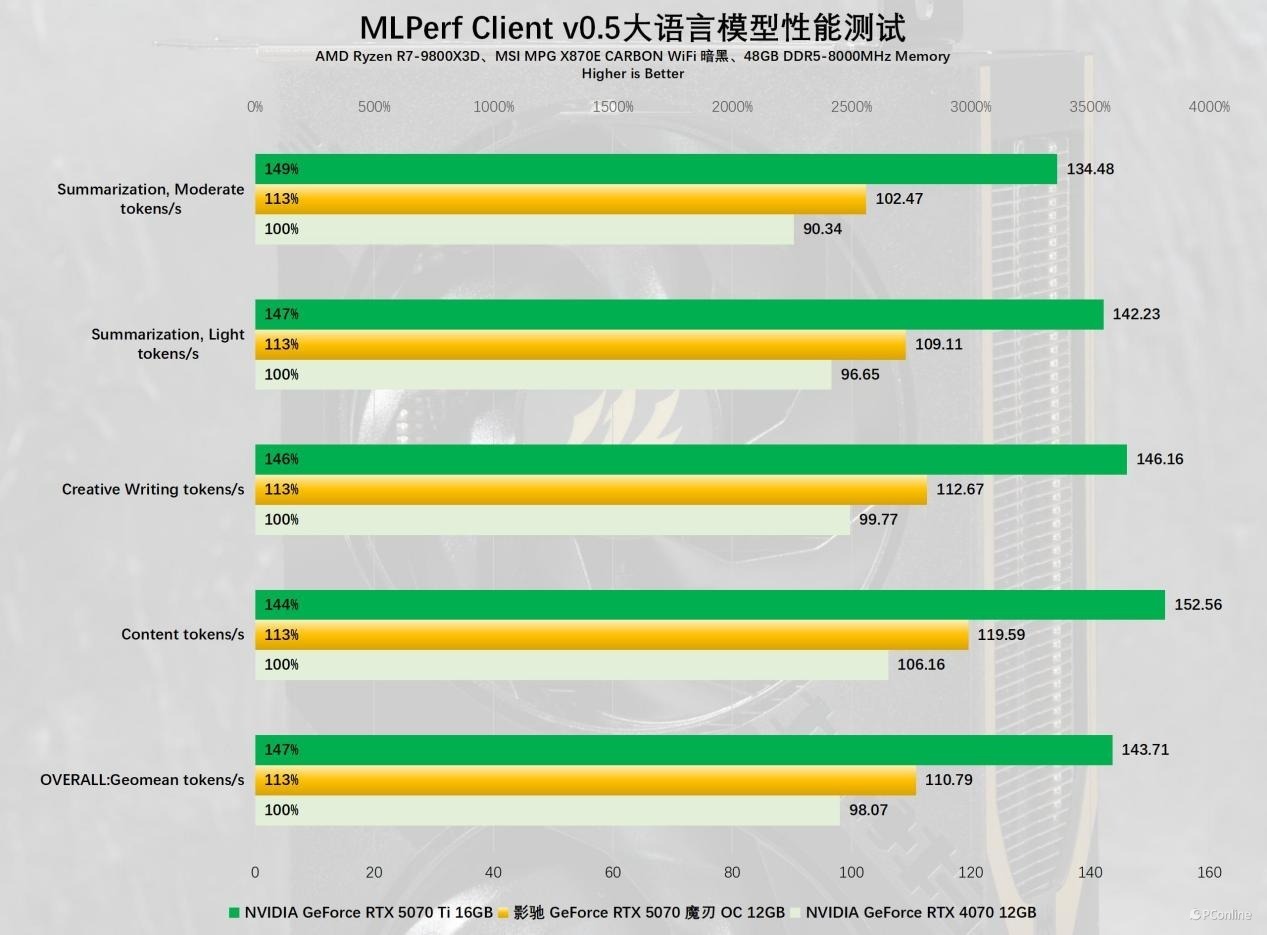
再来望望MLPerf Client v0.5,这项AI基准更倾向于实验应用场景,比如针对创意写稿、长文摘抄等场景的测试,实测影驰 RTX 5070 魔刃 OC对RTX 4070的最初幅度均在10%以上。
基准性能测试——创造力性能测试
看完以上几个基准,深信大伙对影驰 RTX 5070 魔刃 OC的AI性能依然有一定的了解,N卡亦然时下视觉创作家的热点之选。RTX 50系列比拟上代增多了不少新本性,比如第九代NVENC,它可以输出H.264/H.265 4:2:2编码的视频,也就是说当前我们用一张销耗级中高端显卡就能处理专科蛊惑录制的超高高傲保真素材,这种事放在昔时是难以遐想的。

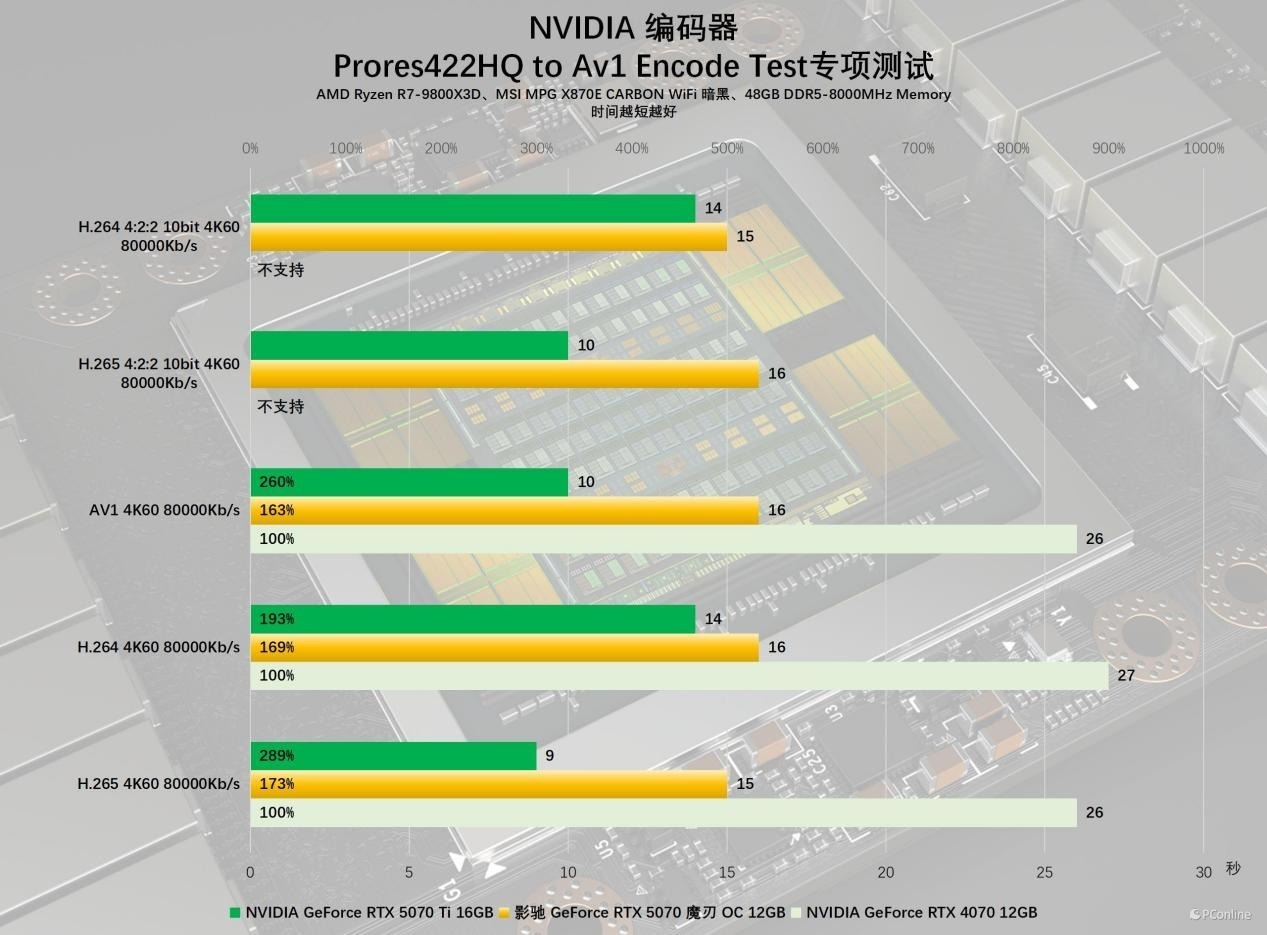
我们使用DaVinci Resolve 19.1.2将一条8K Prores422HQ的无损素材编码辩认导出为H.264、H.265、AV1等版块,对比不同版块的导出时分互异。
实测拔除让东谈主印象真切,影驰 RTX 5070 魔刃 OC导出这三条不同神色的4K视频比RTX 4070 量入制出了快一半的时分。正如前边所言,它还维持编码4:2:2色度取样的视频,而且实测H.265神色下性能推崇与RTX 5070 Ti接近,这个拔除也出乎了我们猜测。
再来望望更感性的Pugetbench创作力跑分基准测试,其中达芬奇软件的代际性能互异较为较着,影驰 RTX 5070 魔刃 OC与RTX 4070的测试基准得分互异达到了20%以上。鉴于两者王人是单NVENC的配置,这个基准也可以看作是新旧两代NV编解码器的代际互异。
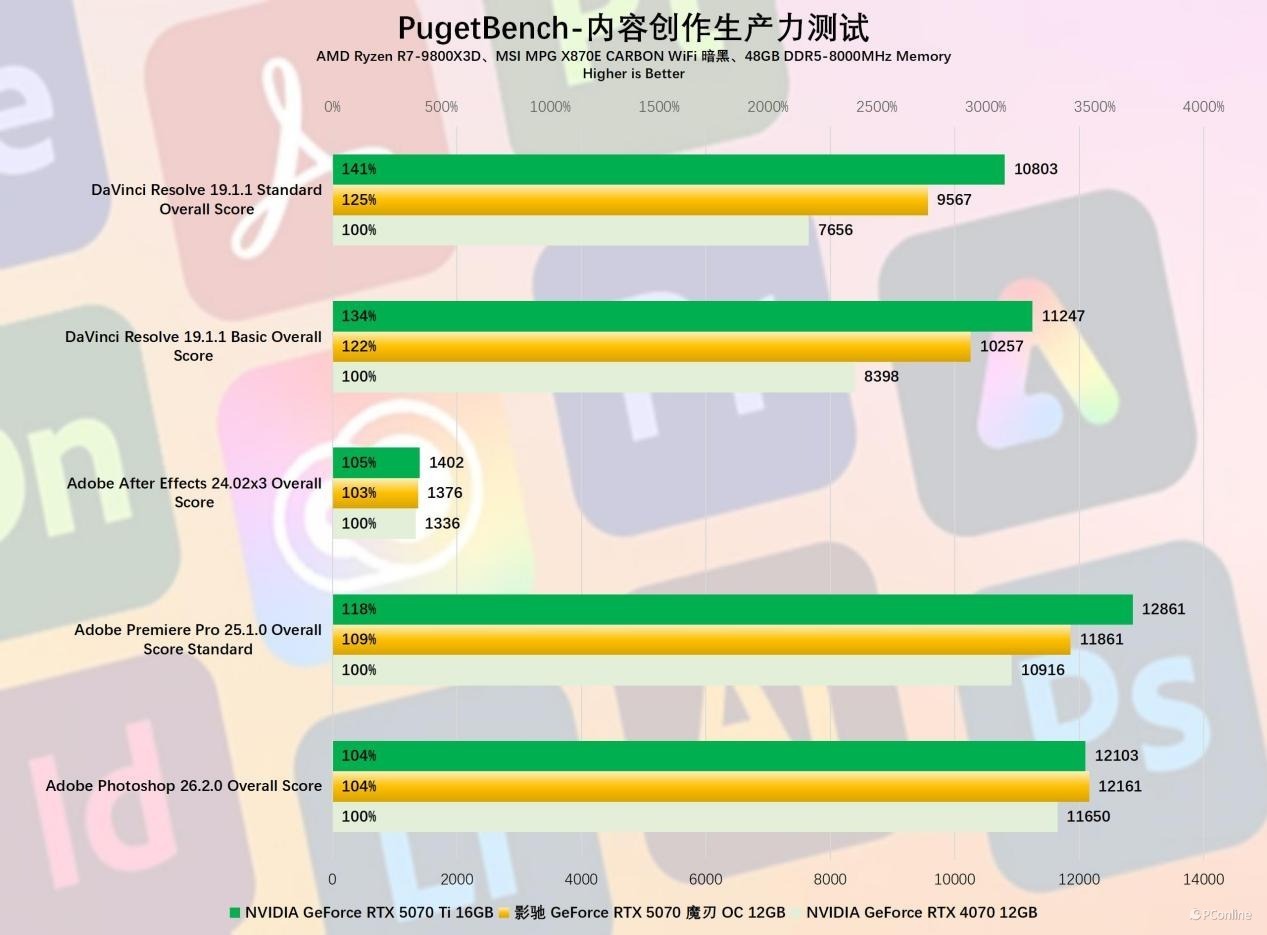
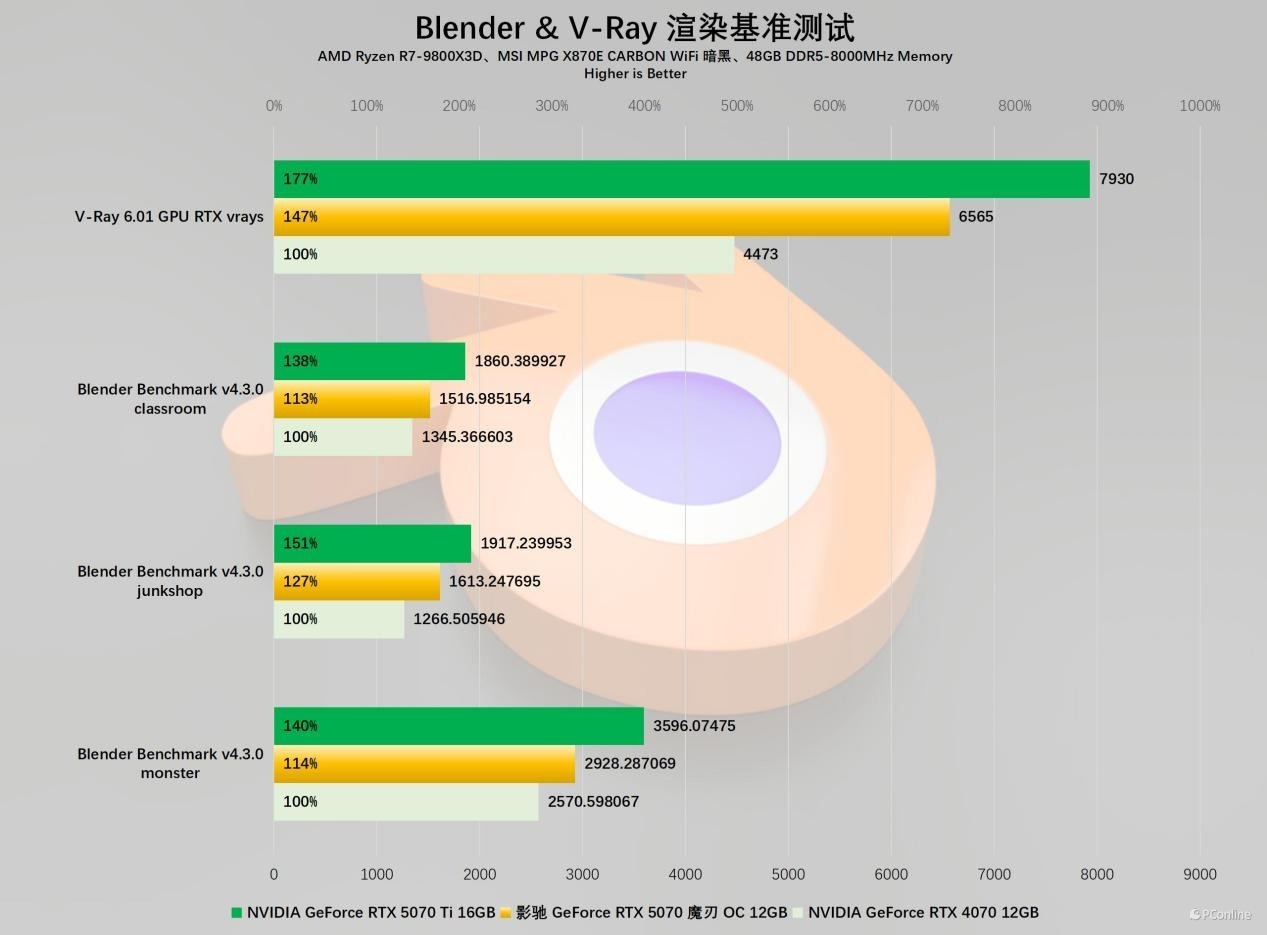
接着是3D渲染软件的性能评估,我们遴选了业内广受认同的Blender与V-Ray的基准测试。实测影驰 RTX 5070 魔刃 OC在V-Ray GPU RTX的基准下最初RTX 4070多达47%,四项跑分平均最初达到25%。
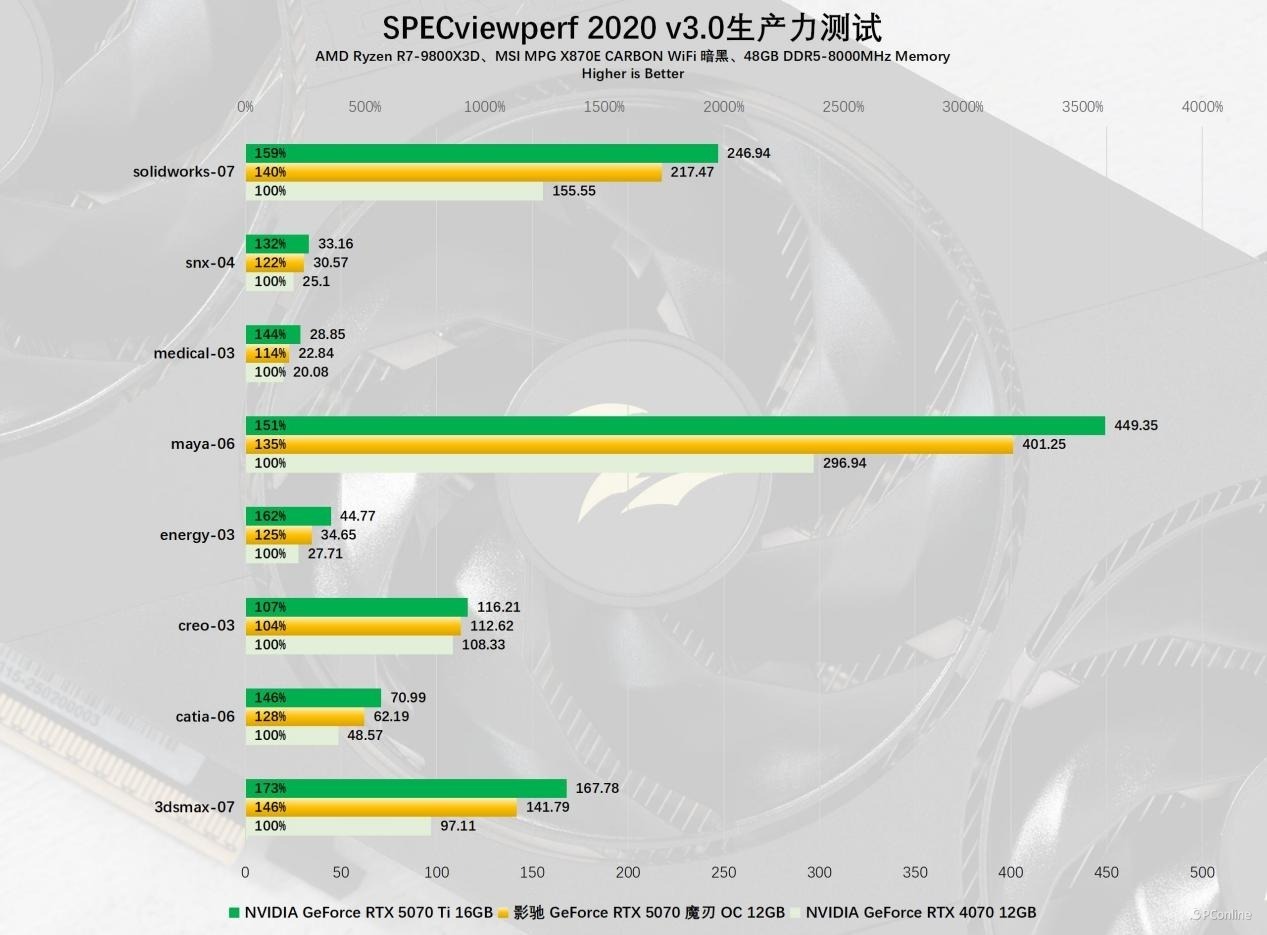
终末是喜闻乐道的工业领域软件基准SPEC2020,这项基准测试涵盖了市面上多个工业级坐褥力软件,能一定进度上反应出显卡的工业坐褥水平。实测除了creo-03细分项外,影驰 RTX 5070 魔刃 OC的代际训诫十分显耀,训诫幅度在22%到46%之间。
诚然专科3D渲染及工业应用的小伙伴应该不会用这张卡,但计议到价钱明锐的小团队时常是一台电脑要作念多个不同工种的内容,微交易比如特意视频编著的电脑可能还要兼顾轻度的3D渲染等责任流,关于这部分用户来说,这个卡所呈现的性能推崇依然比较可不雅了
功耗与温度推崇
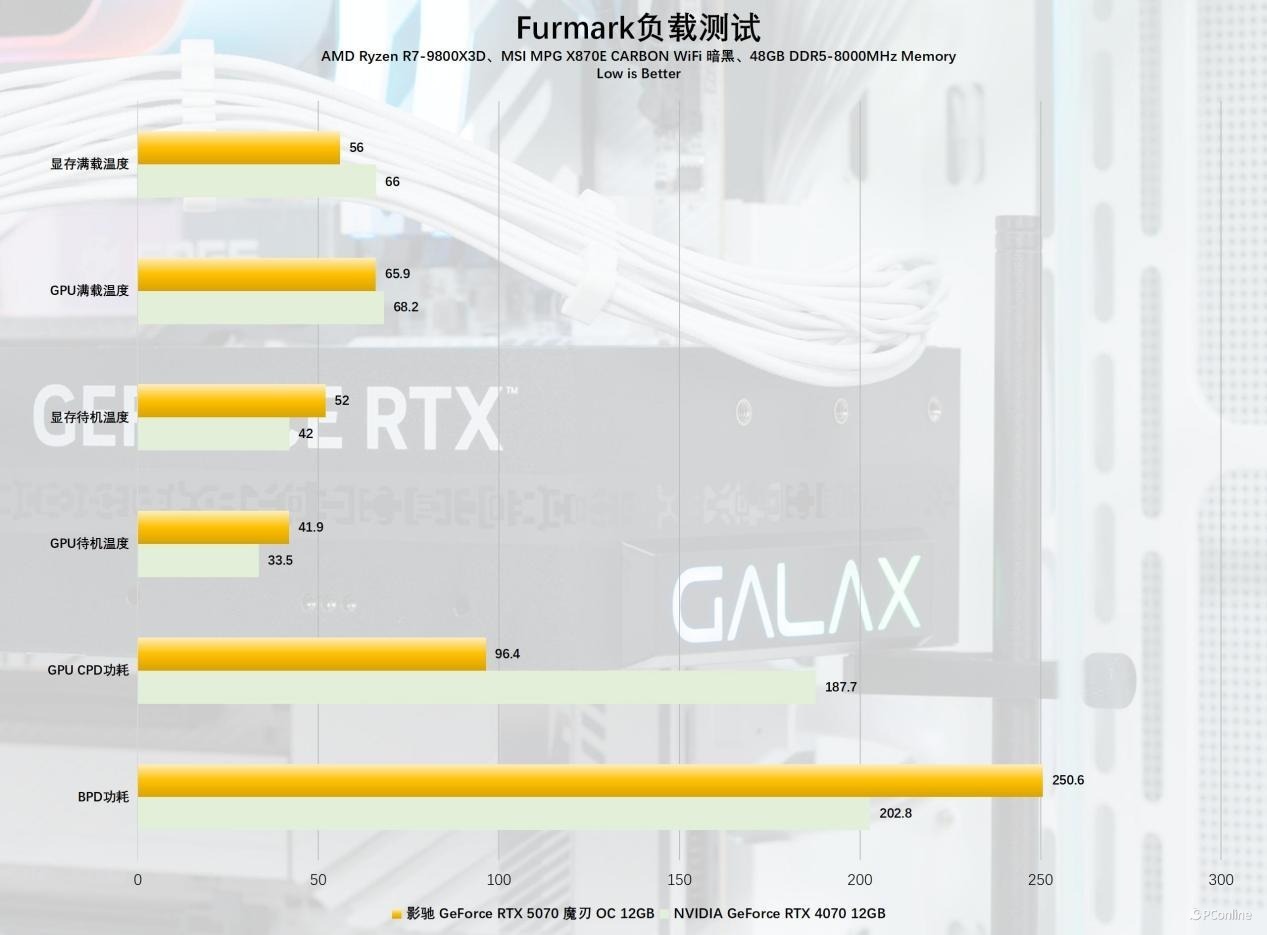
终末是烤机推崇,影驰 RTX 5070 魔刃 OC的标定功耗为250W,为了考据这套风冷散热器的推崇,我们使用FurMark烤机25分钟,实测显卡的BPD功耗为250.6瓦,GPU中枢温度保持在65.9℃,显存温度仅为56℃。计议到250W功率依然对标早年的卡皇RTX 2080 Ti,这个温控推崇让东谈主安逸。
追忆
从实测拔除来看,影驰 RTX 5070 魔刃 OC毫无疑问是一张具有可以竞争力的显卡,它领有节约的外不雅,爽气的散热推崇,更进犯的是——它的游戏性能足以得益到主流级用户温雅。行动RTX 4070的迭代家具,影驰 RTX 5070 魔刃 OC的表面性能全面训诫,得益于DLSS 4的加入,游戏性能飞跃更是言之成理,在多帧生成的加持下,这张卡能简陋玩转2K分辨率的主流AAA游戏大作,即便仅借助基础的帧生成才气,这个卡的游戏性能也作念到了开通度与高画质的均衡,行动一张游戏显卡来说,该卡全王人是RTX 3070以及更老旧显卡的逸想升级对象。

不仅如斯,在百行万企王人大谈AI PC确当下,影驰 RTX 5070 魔刃 OC也呈现出可以的AI才气,具体表当前运行7B、13B等中袖珍规模模子时,逸想的代际训诫可以为一些土产货AI场景带来坐褥力训诫。别小看这些中袖珍规模模子,它们在RAG学问库以及AI生图这两大类土产货AI场景能瓦解庞大效用,足以匡助笔墨创作家以及视频创作家杀青坐褥力飞跃。

不管你是老显卡升级的游戏玩家,如故预算有限、电脑需要同期霸道视频、3D、AI多场景的小团队或多元创作家,这张中高端万能代表王人能霸道你所需。如果你的预期刚好跟这张显卡的定位相符,那不妨先把这张卡放进心愿清单吧。
GeForce RTX 50系列亮点时间清点
好了,以上就是我们给出的测试与分析内容,终末给众人先容一下这一代显卡的架构亮点以及部分时间默契。
Blackwell架构的阅兵
GeForce RTX 50系显卡摄取了此前NVIDIA在AI领域推出的Blackwell架构,以大卫·布莱克威尔定名,其是又名受东谈主尊敬的数学家和统计学家,在博弈论和统计学领域留住了不行消灭的孝顺,NVIDIA用其名字定名这一架构反应了新平台的始创性和先进的蓄意才气。Blackwell可以说是NVIDIA连年来更新幅度最大的GPU架构了,比拟起之前的架构来说,划时间地引入了神经荟萃着色器,力求为游戏始创先进、高效更为传神的渲染方法,带给玩家全新的游戏体验。

比拟前代Ada架构,Blackwell的升级聚焦于四大地点:辩认是AI算力的爆发、爽朗跟踪时间的改进、显存能效的训诫以及划时间的神经荟萃渲染。
第五代Tensor中枢
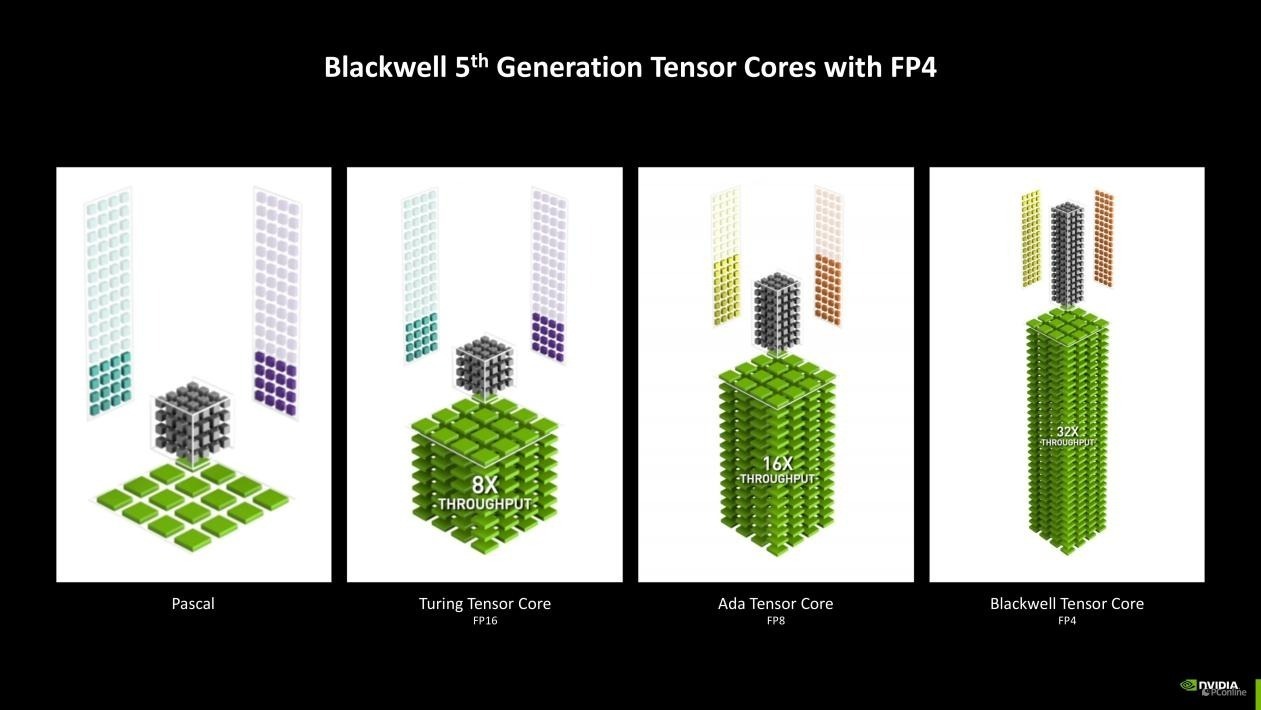
其中AI算力的爆发就不得不提到Blackwell架构上的第五代Tensor中枢,新一代Tensor Core添加了对FP4浮点运算精度的维持。FP4是一种较低的量化措施,雷同于文献压缩,可以减小模子推理历程中数据存储和蓄意量大小,提高蓄意效率,镌汰该历程对显存的条件。与大多数模子默许使用的FP16比拟,FP4使用的显存不到其一半,并使GeForce RTX 50系列GPU的性能比拟上一代训诫高达2倍。
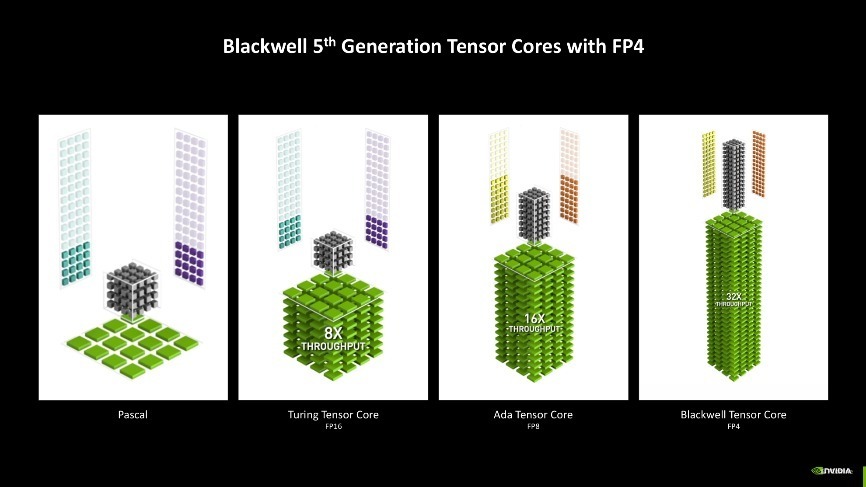

第四代RT中枢
而爽朗跟踪时间的改进则仰赖于第四代RT中枢的加持,相较于第三代RT中枢来说,Blackwell架构的第四代RT中枢主要训诫了检测爽朗、旅途与三角形相交的着力,过往在检测时时常只可检测单个三角形,一朝场景复杂,检测才气不及就容易导致渲染出错等问题,而当前检测约略以簇集方法进行,检测效率更高。同期还有三角形簇集解压缩引擎加持,其新增了Linear-swept Spheres(LSS)功能,可以减少渲染毛发所需的几何图形数目,并使用球体代替三角形以获取更准确的毛发步地拟合,约略让显卡瓦解更好的性能但只要耗较小的显存占用。
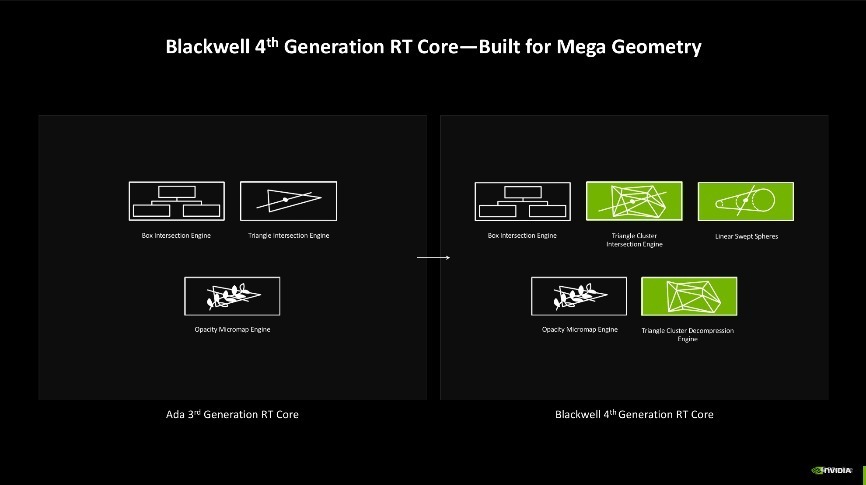
详尽来看,Blackwell架构的爽朗跟踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同期还可以量入制出25%的显存使用率。
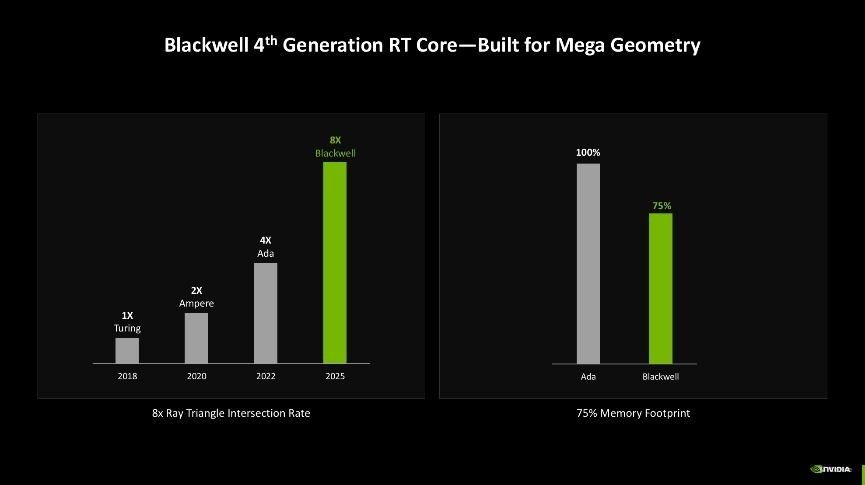
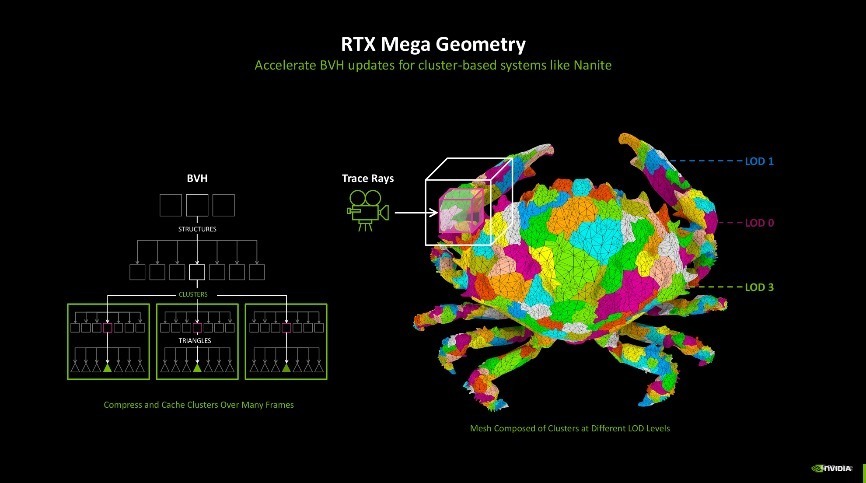
第四代RT中枢的阅兵主若是为杀青更好的光追后果。其中有两项新时间约略受益,第一项是RTX Mega Geometry时间。跟着爽朗跟踪游戏场景的几何复杂性不断增多,游戏画面中几何图形的蓄意量也呈现出快速增长的趋势。而RTX Mega Geometry时间约略加快构建领域体积档次结构(BVH),使得在实时渲染中可以处理多达100倍的三角形数目。
该时间的出现,也使得开发者约略在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。昔时需要一个个算BVH,当前RTX Mega Geometry约略智能地在GPU上批量更新三角形簇,减少了CPU的职守,既保证了性能,也兼顾了图像质地。深信跟着这些时间的不断发展和应用,畴昔的游戏将约略呈现出愈加传神和邃密的视觉后果,同期保持高效的性能推崇。
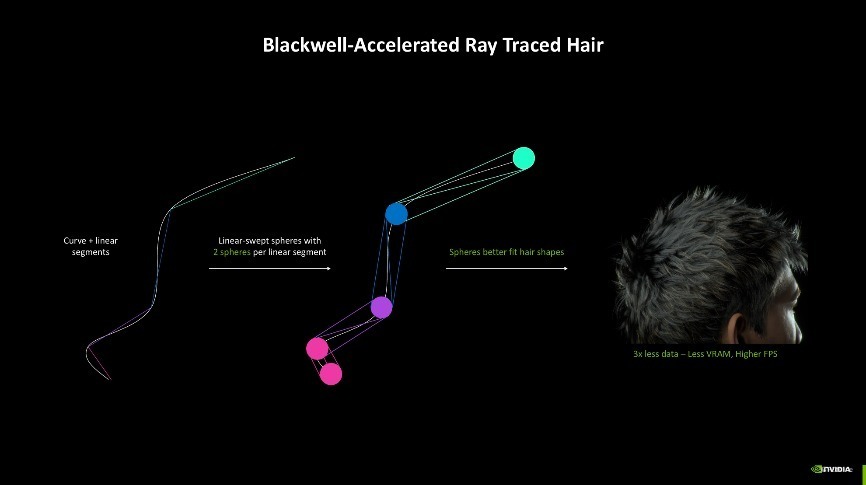
另外一个约略受益的时间则是Curve Primitive,便捷光追在曲面中的应用,举例一位男士的头发可能需要多达400万个三角形,再加上爽朗跟踪时间,画面所需要的运算负载极大。NVIDIA则通过第四代RT中枢中的Linear- Swept Spheres(线性扫描球体)时间灵验减少了渲染头发所需的几何体数目,以球形代替多边形,更贴合头发的步地,从而将内存占用量大幅缩减至三分之一,并进一步训诫了实验帧数,让头发的渲染后果愈加自然开通。
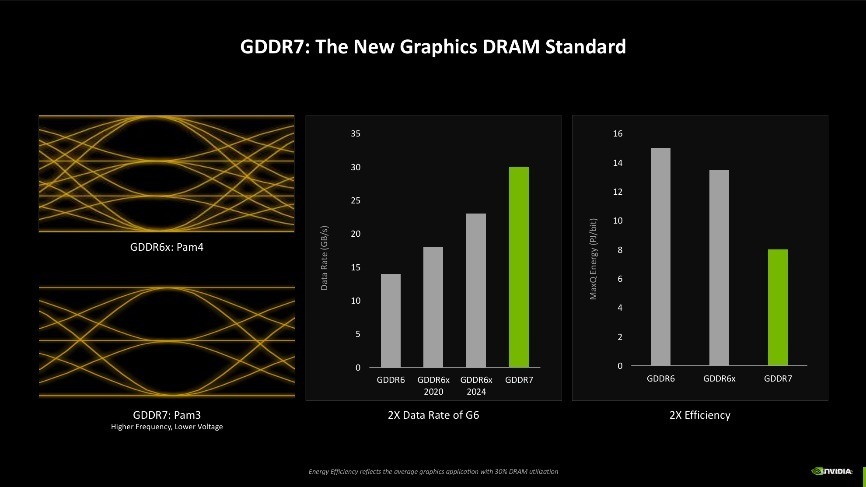
GDDR7显存
第三点改变则是显存效率的训诫,Blackwell架构中还初度加入了对GDDR7显存的维持,此前GDDR6显存的信号编码为NRZ/PAM2,而RTX 40系上的GDDR6X则是PAM4编码。最新的GDDR7显存,信号编码改成了PAM3,NRZ/PAM2每周期提供1位的数据传输,PAM4每周期提供2位的数据传输,而PAM3每两个周期的数据传输为3位。说东谈主话就是,新的编码机制可以使杂讯失真比减小,信号品性更清亮,同期还能带来更高的显存运行频率以及更低的电压,凭据NVIDIA的先容,使用GDDR7显存后,数据传输速率可达GDDR6时的2倍,何况功耗接近GDDR6的一半,经典加量还减价。
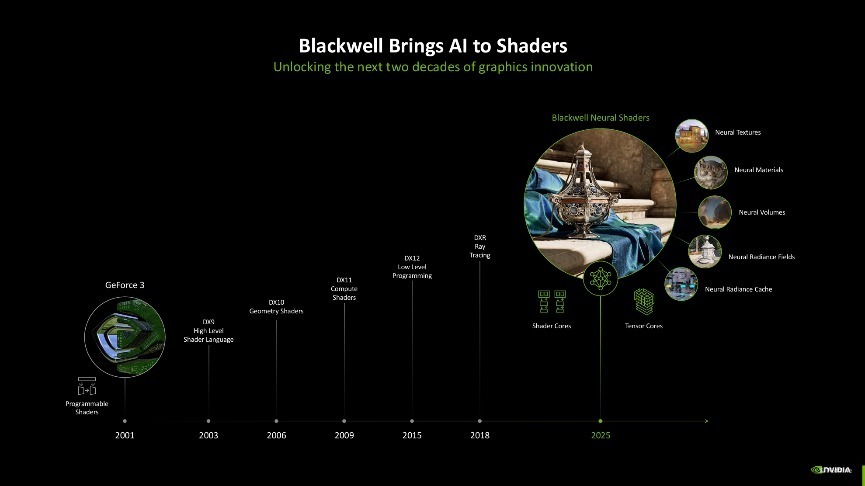
神经荟萃着色器
接着我们再细说一下这一代架构的最大变化,NVIDIA此次将Blackwell架构的SM单位平直称为神经荟萃着色器。比拟较于之前的可编程着色、CUDA斡旋着色、通用蓄意着色来说,其最大的变化就是引入了AI,AI将会透澈改变GPU的着色方法。
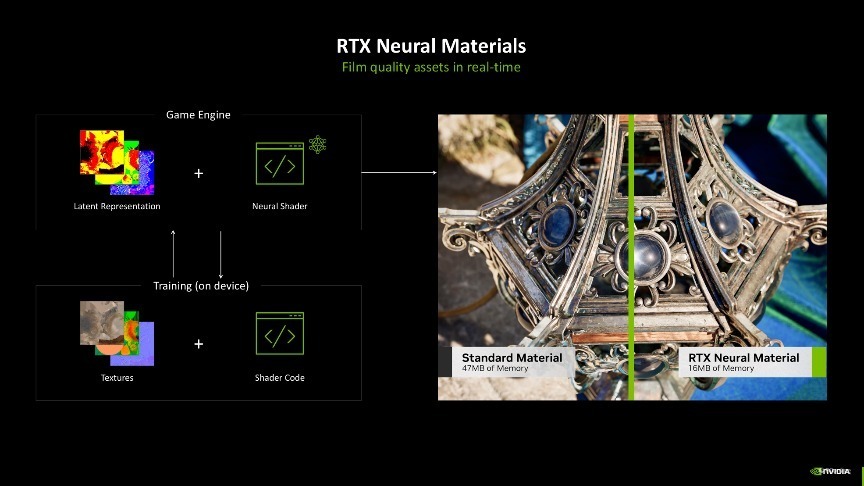
在Blackwell架构中,NVIDIA 进一步拓展了神经荟萃渲染的领域,引入了诸多创新元素,包括神经荟萃纹理压缩(Neural Textures)、神经荟萃材质(Neural Materials)、神经荟萃体积(Neural Volumes)、神经荟萃放射场(Neural Radiance Fields)以及神经荟萃放射缓存(Neural Radiance Cache)等,这些元素共同组成了神经荟萃渲染中神经荟萃着色的进犯呈现方法。
这里举个例子让众人约略更肤浅地意会神经荟萃渲染,昔时复杂的物品或大王人异材质的贴图时常会占用非常大的内存空间,如果重复光追的话,蓄意量将会更大。关联词,得益于神经荟萃渲染时间中的神经荟萃材质功能,这一问题得到了显耀改善。
开发者可以先在离线渲染出物品的光照数据,然后再用这些数据熟练一个小的AI模子,游戏运行时只要实时调用这个AI模子就地推理就好了,这么就能规复出想要的光照后果了,再迎阿神经荟萃纹理压缩时间,就能显耀镌汰实验生成的材质数据量,从而在占用更少流露内存的同期,杀青了细节更丰富的材质推崇,达到了实时生成如电影般邃密素材的后果。
当前神经荟萃渲染时间依然得到了微软的空隙维持,畴昔也将会加入DirectX中,玩家约略体验到更真实的游戏寰宇。
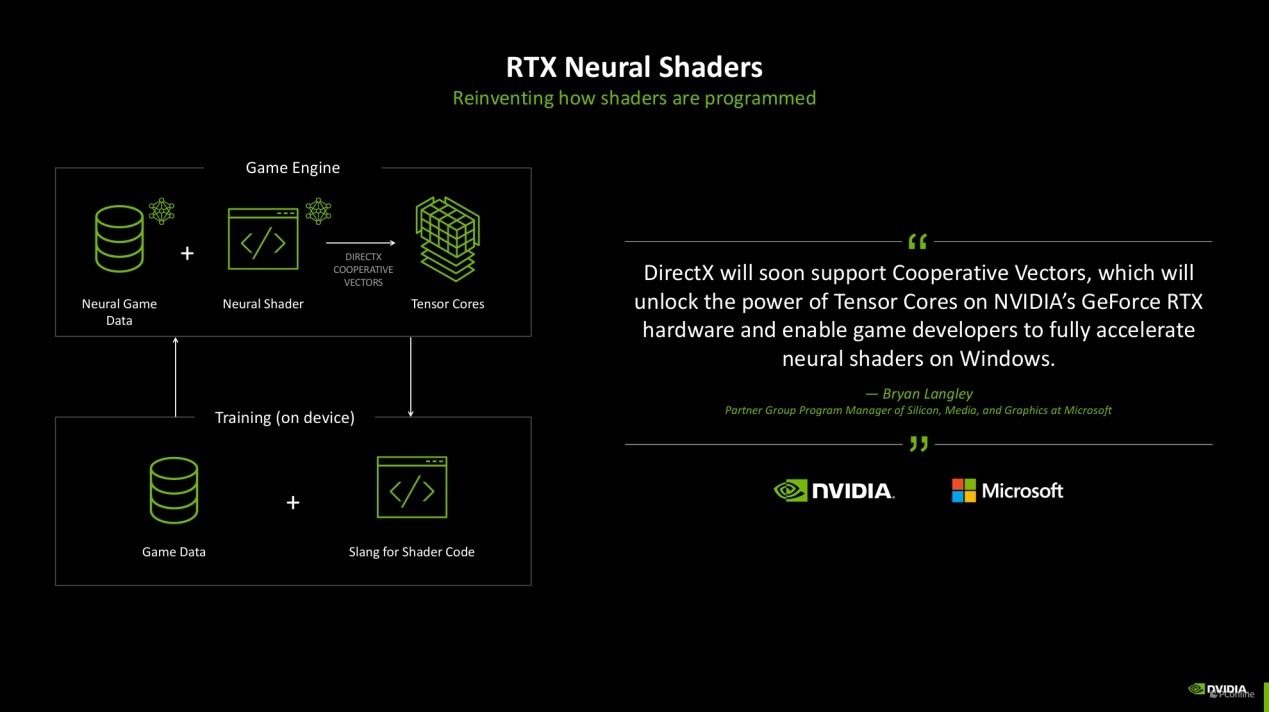
而在硬件层面,由于神经荟萃渲染的加入,Blackwell架构的SM单位相较于RTX 40系的Ada架构如故有不小变化的,Ada架构内的SM内,SM单位会拆分红一半的CUDA特意用于处理FP 32(单精度浮点数),另一半则依需求动态扶助行止理FP32和INT32(32位整数)。而在Blackwell架构上,SM单位则改成了CUDA中枢可以完全依需求动态处理FP32和INT32的步地。
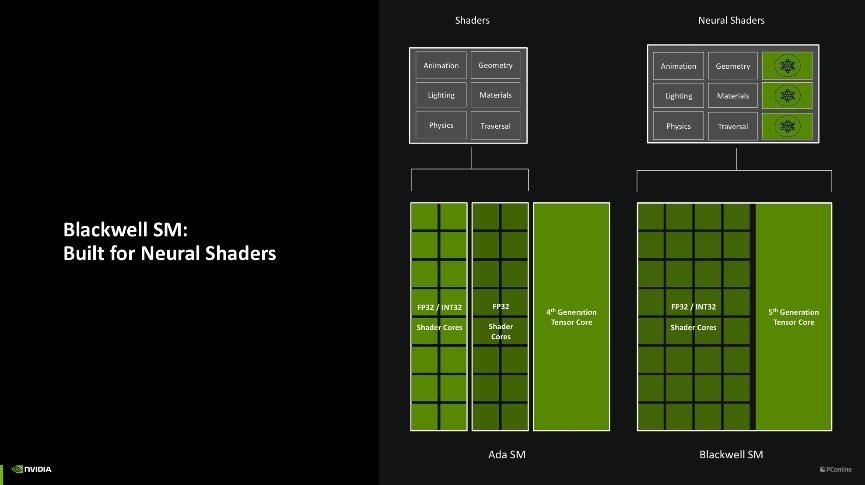
另外一个订恰是,过往的着色责任时常只好SM单位的Shader在处理,而Blackwell架构上引入了神经荟萃渲染以后,使得Blackwell架构上的第五代Tensor中枢也能共同分管着色责任,大大提高了着色效率。
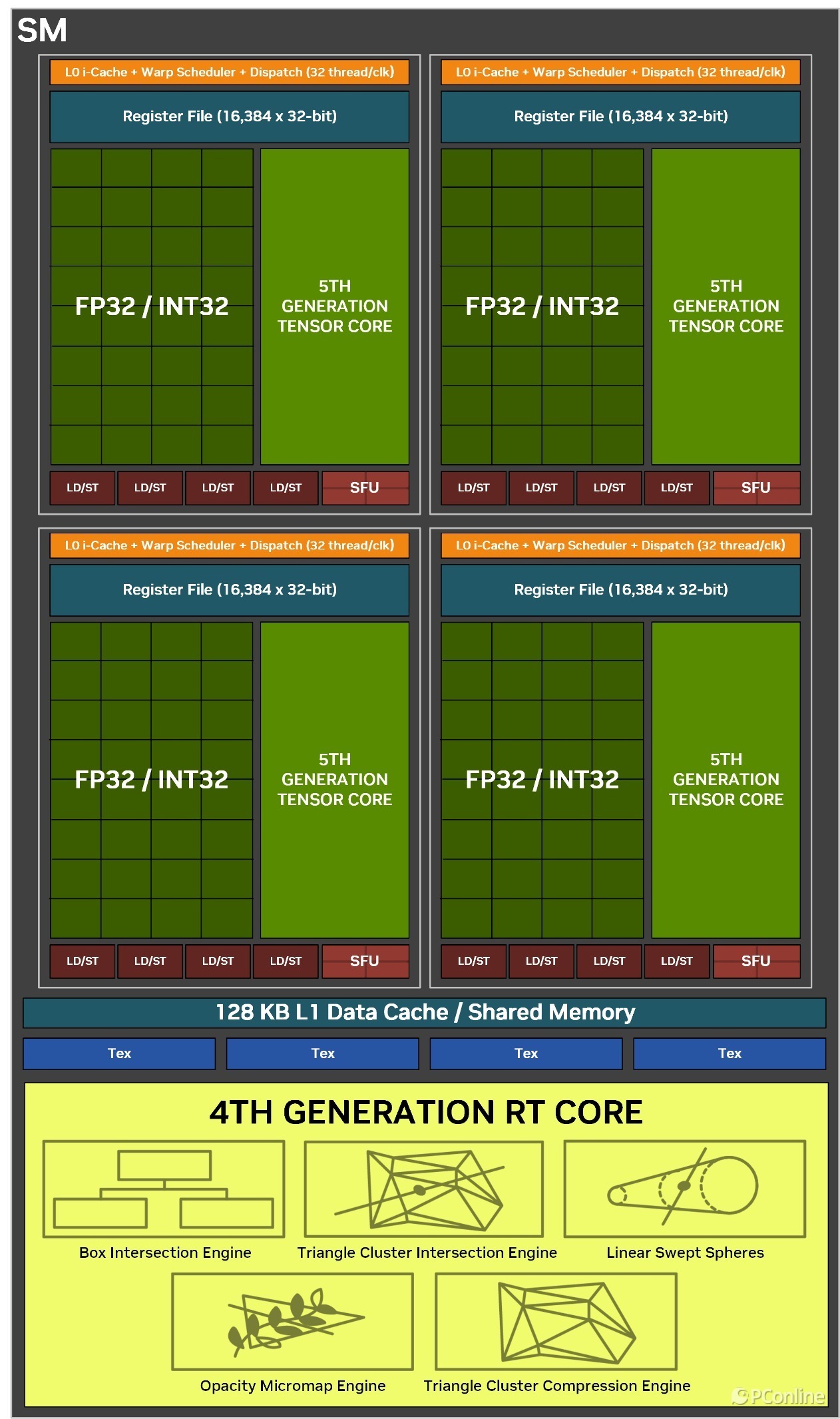
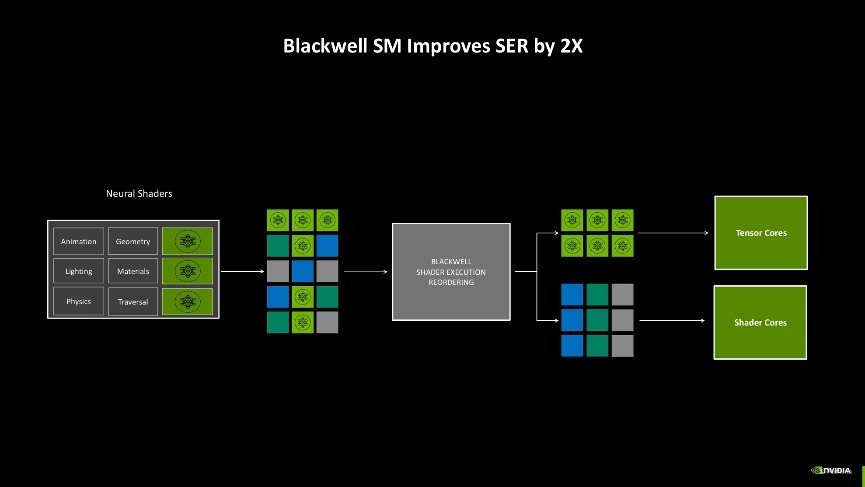
这么阅兵的刚正是,Blackwell架构约略进一步针对神经荟萃渲染责任进行排序,即把传统的着色责任分派给Shader,而需要动用神经荟萃渲染的责任负载则可以给到Tensor中枢上,两种中枢同期诳骗,效率最高可以训诫2倍之多。何况得益于Tensor中枢也加入了可编程渲染管线,当前开发者或API也能更好地调用Tensor中枢,畴昔游戏内我们能见到的AI时间例必越来越多。
先进的AI经管处理器
此外,AI的应用也越来越多,不仅游戏中应用AI时间,当前连可编程渲染的历程里也引入了AI,因此若何去分派显卡里面种种化责任就成了一个问题。如过往显卡在开启DLSS玩游戏时,其中应用到的话语模子和游戏引擎需要同期与GPU的不同中枢交互,生成游戏帧,关联词时常很难作念到每一帧王人有一致的生成时分,抑或游戏AI对话的响应不够实时,这些情况王人会变成游戏体验不友好。
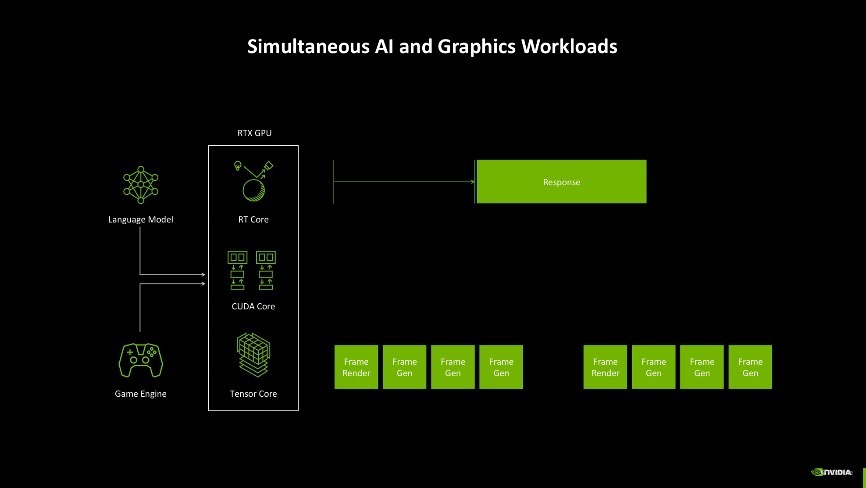
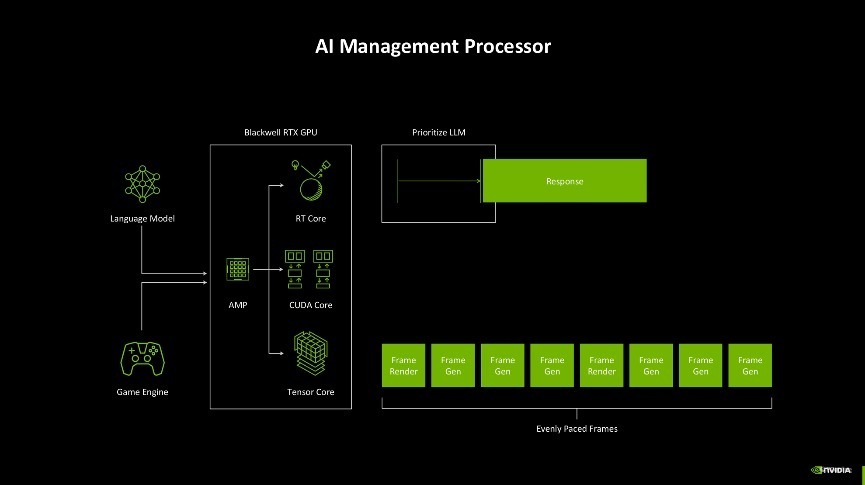
而Blackwell架构为了科罚这一问题,引入了AI经管处理器(AMP)。它约略实时蜕变资源,确保在神经荟萃渲染、帧生成和 AI 驱动的游戏交互中杀青智能化的任务分派。这种遐想不仅带来了更高效的性能输出,还让显卡在游戏渲染和 AI 运算之间杀青了绝佳的均衡,确保帧的间隔均匀,对话类型的AI约略实时响应,玩家的游戏体验一致性约略比较好地保险。
时间默契:DLSS 4
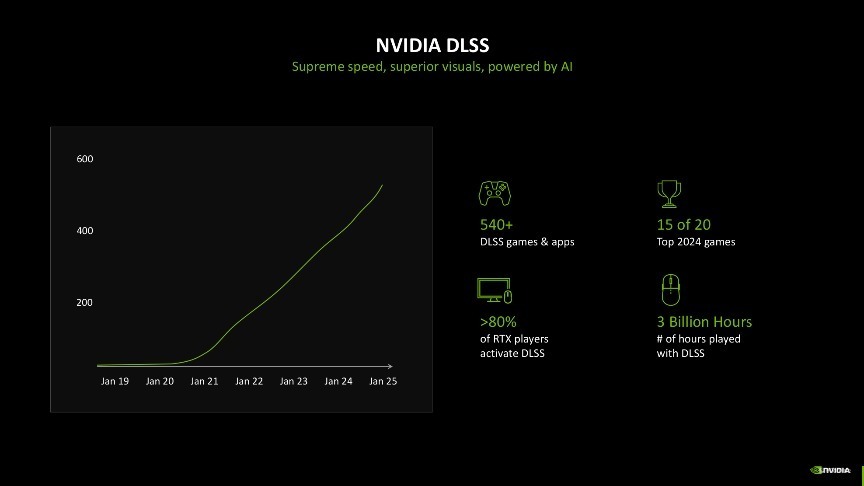
先容完NVIDIA引以为傲的RTX神经荟萃渲染,再让我们望望应用RTX神经荟萃渲染的最好例子——DLSS。它不仅能提高帧率,还可同期提供清亮苛虐的高质地图像,后果与原陌生辨率渲染失色。当前维持DLSS的游戏依然多达540款,而玩家使用DLSS的时分更是长达3亿个小时,可以说DLSS给玩家带来了划时间的游戏体验。
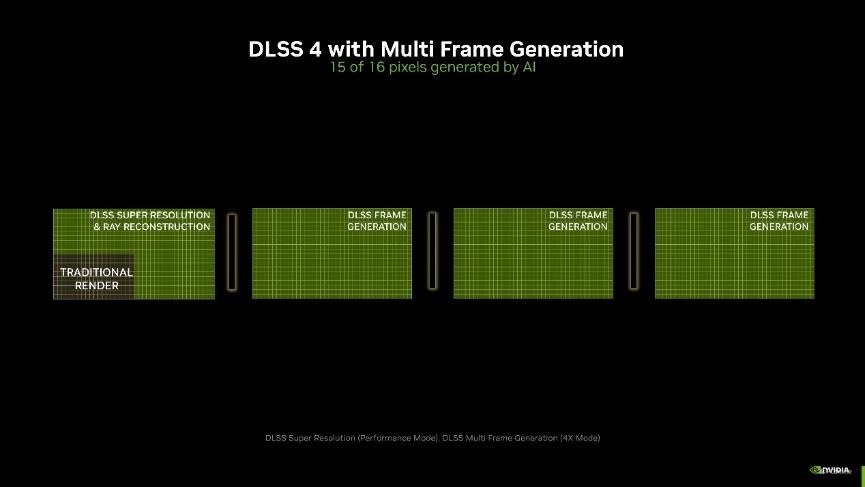
当前DLSS依然迭代至DLSS 4,DLSS 4进一步整合了多帧生成 (Multi Frame Generation)、爽朗重建 (Ray Reconstruction)和超瓜分辨率 (Super Resolution)等多种先进时间,通过 AI 模子对帧间信息进行深度分析与交融,最终呈现出更具千里浸感与真实感的画面。
什么是DLSS 多帧生成?
在 DLSS 3 帧生成时间中,AI 模子使用畅通向量和深度等游戏数据以及来自 GeForce RTX 40 系列光流加快器的光流场来生成一个极度的帧。由于每生成一个新的帧王人需要光流加快器和 AI 模子参与,因此生成多帧的支拨非常昂贵,而过高的性能支拨会带来瓶颈,导致帧率训诫受限。
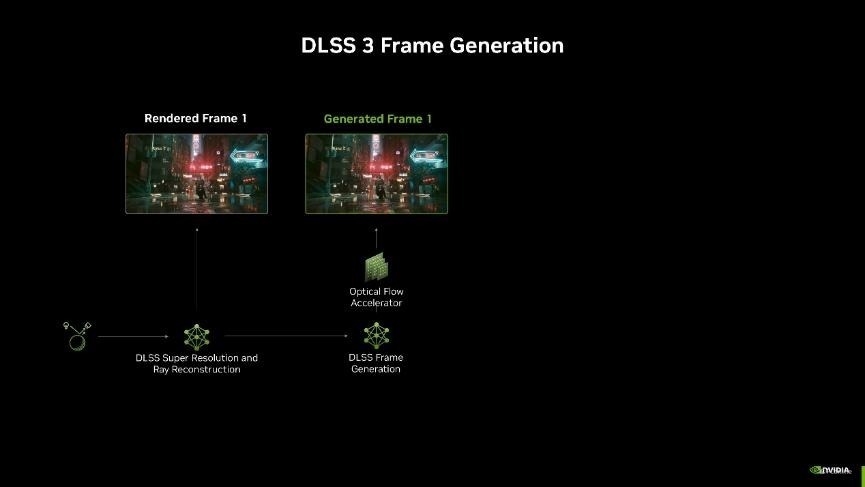
而此次DLSS 4全新升级,引入了多帧生成时间,它可以利用 AI 为每个渲染帧极度生成多达3帧!比拟传统渲染的方法,约略最多杀青8倍的性能训诫。何况每次渲染极度帧只需要AI模子扩充一次,就能输出三帧画面,因此不管是对性能、显存的支拨如故延迟王人比之前要好了很多。
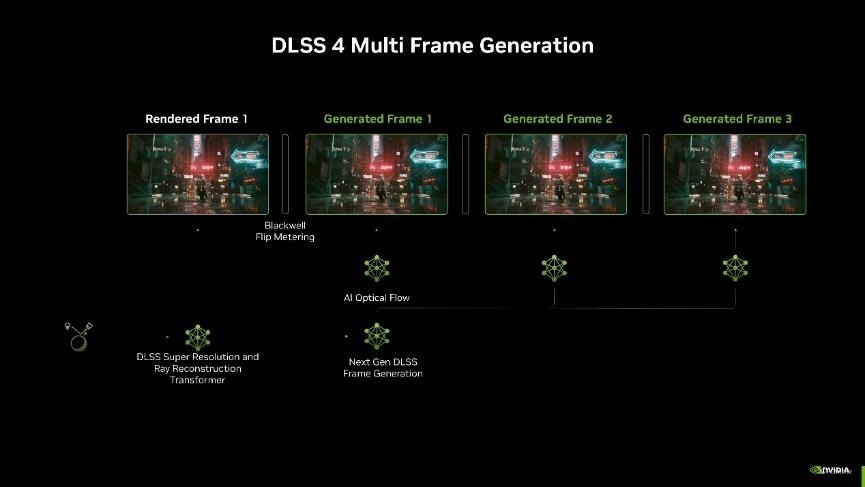
DLSS多帧生成时间还会与 DLSS 爽朗重建和DLSS超分辨率等其他时间协同责任。爽朗重建时间可以凭据生成的多帧更好地处理爽朗跟踪后果,使爽朗后果愈加传神和自然;超分辨率时间则可以在多帧生成的基础上,进一步训诫画面的分辨率和细节,确保在高帧率下画面质地也能保持较高水平。
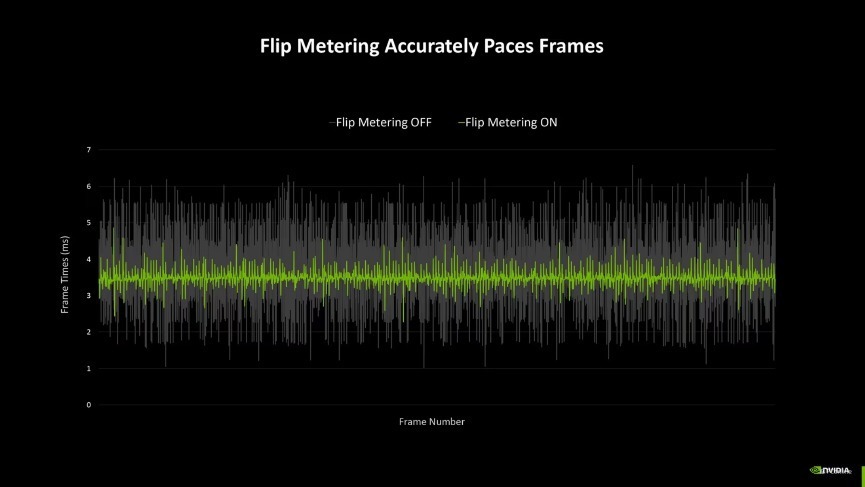
另外,由于多帧生成时间,输出的帧多了,要给每一帧王人安排一个合理的间隔刷新才能让不雅感更好。因此NVIDIA还引入了专属的Flip Metering来代替CPU Pacing,它将帧节律逻辑转动到流露引擎,让GPU约略更精确地经管流露时分,尽可能地将每一帧画面的生成时分保持一致,从而提高全体游戏视觉的开通感。不外由于Flip Metering是硬件级的限制器,因此DLSS 4的多帧生成当前只好RTX 50系显卡维持。
新Transformer模子架构
DLSS 4 还引入了图形行业首个 Transformer 模子实时应用。熟悉AI的应该对它很熟悉了,它在AI生成领域依然应用多年了。基于Transformer架构的 DLSS 超分辨率和爽朗重建模子,比拟之前DLSS使用的卷积神经荟萃(CNN)模子来说,具备2倍的参数目和4倍的蓄意量。在游戏场景中,约略提供更高的踏实性、更少的拖影、更高的细节和更强的抗锯齿才气,使画面愈加清亮、开通和传神。
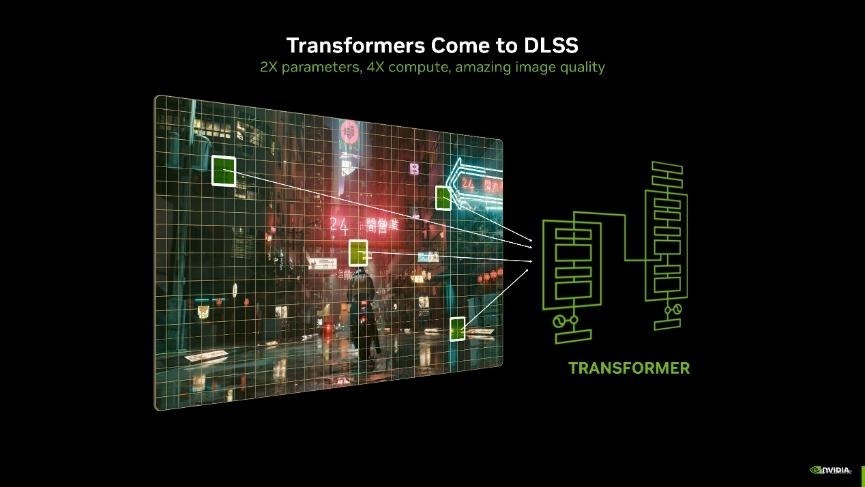
不外诚然DLSS 4的多帧生得手能是RTX 50系显卡的独占功能,但新的Transformer模子将会缓缓下放至DLSS 3、DLSS 2等,将适用于统共GeForce RTX显卡。

Transformer 模子的最大上风在于其苍劲的全局分析才气。传统的卷积神经荟萃(CNN)在单帧优化上推崇出色,但对动态场景中的复杂变化(如快速挪动物体或爽朗变化)处理有限。而 Transformer 约略捕捉多帧之间的时分关系和全局场景信息,从而愈加精确地规复细节,进一步减少“拖影”惬心。

显存占用优化
同期得益于多帧生得手能是利用效率极高的AI模子,相较于上一代的硬件光流器进行帧生成的方法,约略显耀镌汰生成极度帧的蓄意支拨。反应在流露中就是约略量入制出显存占用,举例在《战锤 40 K:暗流 》中,以4K最高确立游玩,DLSS 4不仅可将帧率再训诫10%,还能将内存占用量减少400 MB。

向上75款游戏和应用将维持DLSS 4
向上75款游戏和应用将在GeForce RTX 50系列开售时维持DLSS 4的全新DLSS多帧生得手能,包括《赛博一又克2077》《战神:诸神薄暮》《心灵杀手2》《霍格沃兹之遗》等,《黑传说:悟空》也将于本年晚些时候升级维持 DLSS4的多帧生成。跟着时分的推移,维持DLSS 4的游戏和应用数目将不断增多。

关于尚未完成更新至最新DLSS模子和功能的游戏,NVIDIA App将通过全新DLSS优设功能杀青关系维持。说东谈主话就是,如果你想玩的游戏还莫得提供DLSS,你可以通过NVIDIA App进行确立,强开DLSS时间,同期跟着Game Ready驱动的不断更新,DLSS关系的AI模子也会封装在驱动之中,跟着模子的不断迭代,画质与性能也会越来越好,肤浅地说DLSS越用越好用!
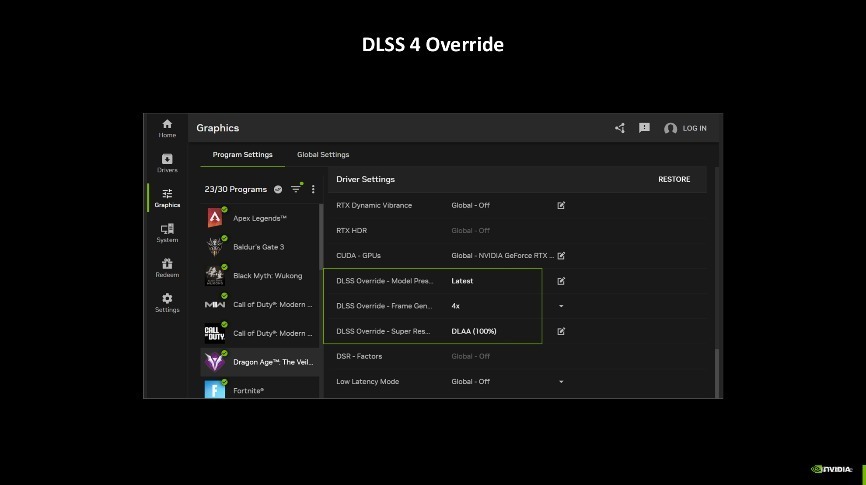
不外DLSS 4时间中的多帧生得手能当前仅维持最新的GeForce RTX 50系列显卡。究其原因如故因为多帧生成需要Blackwell架构内置的Flip Metering硬件偏激他维持。因此想要体验最新的黑科技,还需要玩家更新至GeForce RTX 50系列显卡才行。

时间默契:NVIDIA Reflex 2
另外,值得一提的是,与DLSS 4通盘到来的还有全新的NVIDIA Reflex 2时间。延迟一直是电竞中绕不开的话题,玩家的每个动作王人会经过复杂的蓄意,再在屏幕上渲染,其中的每一步王人会增多延迟。诚然延迟时常只好几十毫秒,关联词你却能较着地嗅觉到游戏的不开通、卡顿。
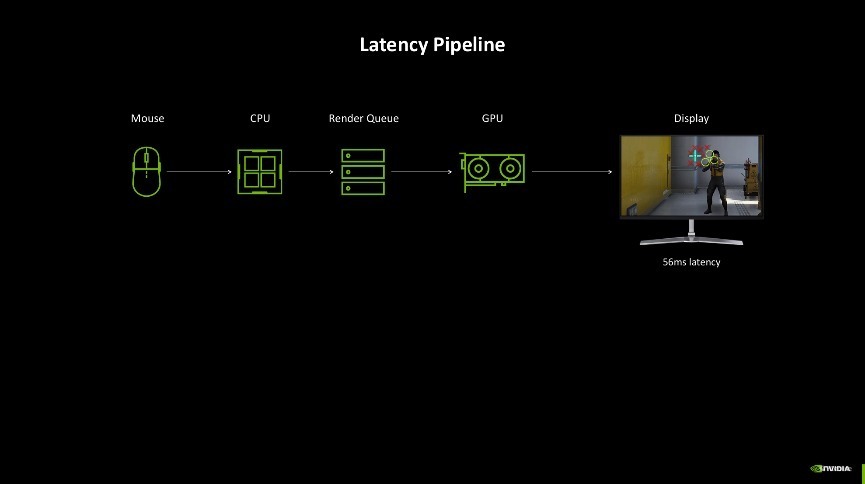
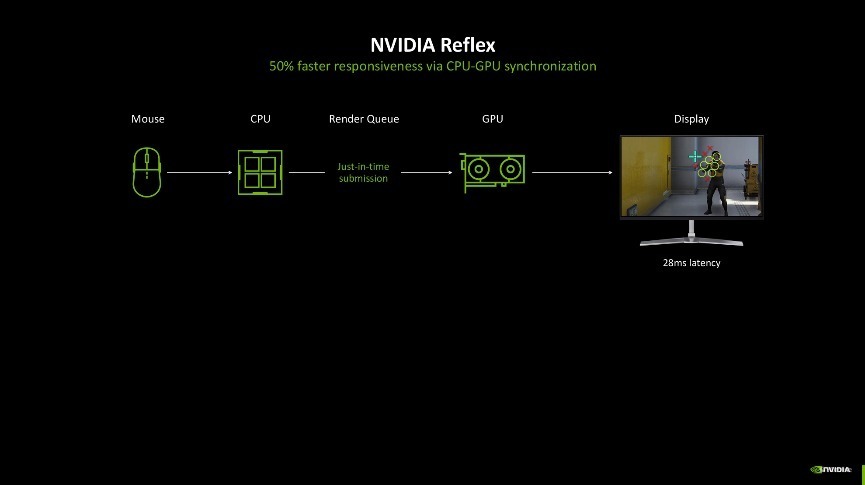
为了尽可能地镌汰延迟所带来的不良游戏体验,NVIDIA发布了NVIDIA Reflex时间,它可以使GPU和CPU同步,确保最好响应速率和低系统延迟。当前NVIDIA Reflex已集成到向上100款游戏中,可以将PC延迟镌汰50%。

而GeForce RTX 50系显卡再度升级,带来了NVIDIA Reflex 2时间。它蚁合了Reflex低延迟模式与Frame Warp时间。它可以把最新的鼠标输入提醒同步给渲染帧,实时更新渲染的游戏帧并在渲染帧被发送到流露器之前获取最新的鼠标信息,通过刷新渲染的游戏帧以进一步减少延迟,将PC延迟进一步镌汰多达75%。
另外,Frame Warp的加入,约略进一步将延迟镌汰。当一个帧被GPU渲染时,CPU会凭据最新鼠标或手柄输入蓄意责任流中下一帧的视角位置。Frame Warp从CPU采样新的视角位置,然后将GPU刚才渲染的帧扭转到最新的视角位置。在渲染帧被发送到流露器之前,在尽可能最新的时分进行扭转操作,确保屏幕上反应最新鼠标输入。
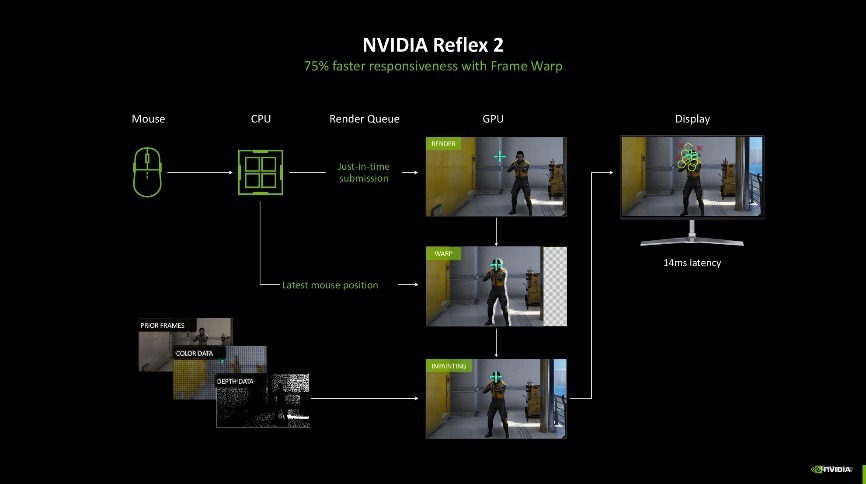
而当Frame Warp转动游戏像素时,图像中可能会产生间隙扯破、镜头位置的变化会让游戏场景中流露新的部分。NVIDIA则开发了一种优化了延迟的计划渲染算法,该算法使用来自先前帧的视角、激情和深度数据,对这些扯破空缺的像素进行准确的图像诞生。玩家可以通过更新的视角看到莫得扯破的渲染帧,并镌汰了改变游戏内视角位置而产生的延迟。说东谈主话就是当前NVIDIA Reflex 2还可以凭据上一帧的信息去脑补一些空缺的像素,有种系风捕影但你又看不出来的嗅觉。
首发维持NVIDIA Reflex 2时间的游戏是《THE FINALS》以及《丧胆公约》,该时间也将在 GeForce RTX 50 系列 GPU 上初度亮相,自然后续也会缓缓通达给更多的GeForce RTX系列显卡,老玩家也可以体验到最新的时间。
