


近日,Picsart AI Resarch 等团队蚁集发布了 StreamingT2V,可以生成长达 1200 帧、时长为 2 分钟的视频,一举越过 Sora。
同期,手脚开源寰球的苍劲组件,StreamingT2V 可以无缝兼容 SVD 和 animatediff 等模子。
120 秒超长 AI 视频模子来了!不但比 Sora 长,而且免费开源!
Picsart AI Resarch 等团队蚁集发布了 StreamingT2V,可以生成长达 1200 帧、时长为 2 分钟的视频,同期质料也很可以。

论文地址:https://arxiv.org/ pdf / 2403.14773.pdf
Demo 试用:https://huggingface.co/ spaces / PAIR / StreamingT2V
开源代码:https://github.com/ Picsart-AI-Research / StreamingT2V
况兼,作家暗意,两分钟并不是模子的极限,就像之前 Runway 的视频可以延伸相通,StreamingT2V 表面上可以作念到无穷长。

在 Sora 之前,Pika、Runway、Stable Video Diffusion(SVD)等视频生成模子,一般只可生成几秒钟的视频,最多延伸到十几秒。

Sora 一出,60 秒的时长径直秒杀一众模子,Runway 的 CEO Cristóbal Valenzuela 本日便发推暗意:比赛最先了。

—— 这不,120 秒的超长 AI 视频说来就来了。
这下虽说不行飞速撼动 Sora 的总揽地位,但至少在时长上扳回一城。
更进攻的是,StreamingT2V 手脚开源寰球的苍劲组件,可以兼容 SVD 和 animatediff 等神色,更好地促进开源生态的发展:

通过放出的例子来看,当今兼容的后果还稍显玄虚,但时候进步仅仅时刻的问题,卷起来才是最进攻的~
总有一天咱们都能用上「开源的 Sora」,—— 你说是吧?OpenAI。
免费开玩
当今,StreamingT2V 已在 GitHub 开源,同期还在 huggingface 上提供了免费试玩,等不明晰,小编飞速开测:
不外貌似劳动器负载太高,上头的这个不知说念是不是恭候时刻,归正小编没能见效。
当今试玩的界面可以输入笔墨和图片两种领导,后者需要鄙人面的高等选项中开启。
两个生成按钮中,Faster Preview 指的是离别率更低、时长更短的视频。
小编于是转战另一个测试平台(https://replicate.com/ camenduru / streaming-t2v),终于赢得一次测试契机,以下是笔墨领导:
A beautiful girl with short hair wearing a school uniform is walking on the spring campus
不外可能由于小编的要求比较复杂,导致生成的后果些许有点惊悚,各位可以凭证我方的教学自行尝试。
以下是 huggingface 上给出的一些见效案例:
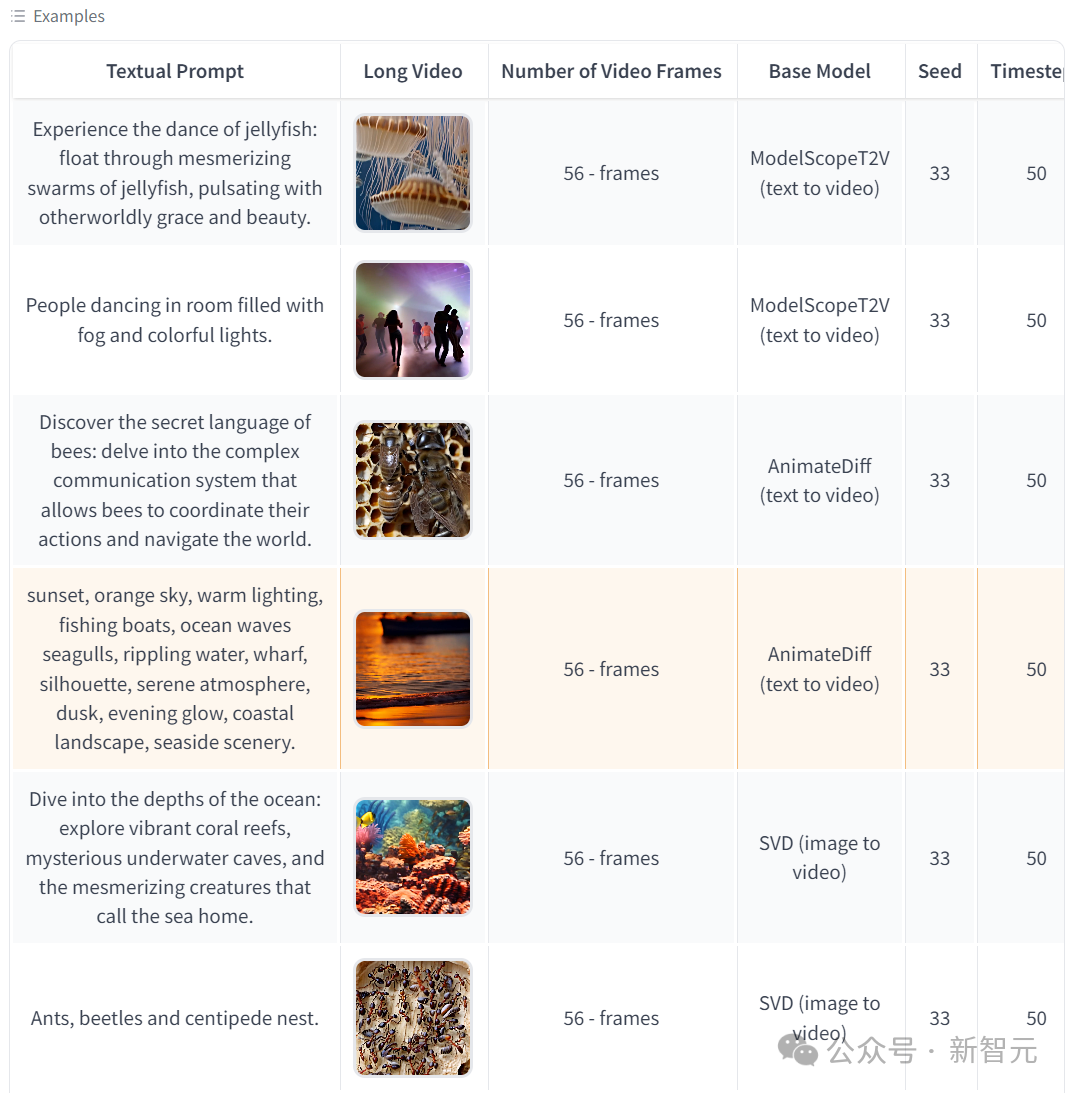
StreamingT2V

「寰球名画」
Sora 的横空出世曾带来广阔的震憾,使得前一秒还闪闪发光的 Pika、Runway、SVD 等模子,径直造成了「前 Sora 时间」的作品。
不外就如同 StreamingT2V 的作家所言,pre-Sora days 的模子也有我方的专有魔力。

模子架构
StreamingT2V 是一种先进的自归来时候,可以创建具有丰富主见动态的长视频,而不会出现任何停滞。
它确保了所有这个词视频的时刻一致性,与描述性文本良好对都,并保捏了高帧级图像质料。
现存的文本到视频扩散模子,主要聚集在高质料的短视频生成(频繁为 16 或 24 帧)上,径直膨胀到长视频时,会出现质料下落、进展生硬或者停滞等问题。

AI 生成视频
而通过引入 StreamingT2V,可以将视频膨胀到 80、240、600、1200 帧,致使更长,并具有平滑过渡,在一致性和主见性方面优于其他模子。
StreamingT2V 的要津组件包括:
(i)称为要求防卫力模块(CAM)的短期牵记块,它通过防卫机制凭证从前一个块中提真金不怕火的特征来改动当前一代,从而竣事一致的块过渡;
(ii)称为外不雅保留模块(APM)的弥远牵记块,它从第一个视频块中提真金不怕火高等场景和对象特征,黄金投资以防护模子健忘运行场景;
(iii)一种偶然羼杂步调,该步调大要对无穷长的视频自动归来应用视频增强器,而不会出现块之间的不一致。
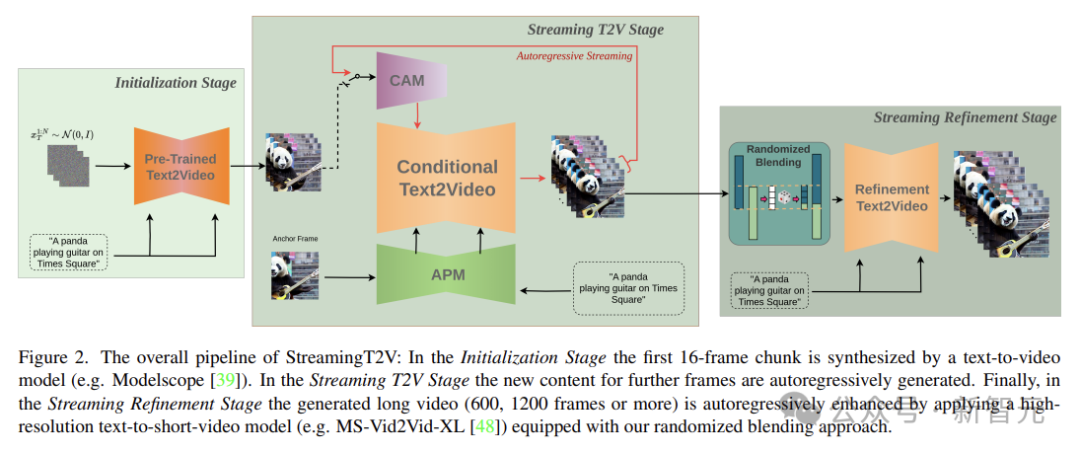
上头是 StreamingT2V 的全体活水线图。在运行化阶段,第一个 16 帧块由文本到视频模子合成。在流式处理 T2V 阶段中,将自动归来生成更多帧的新现实。
临了,在流优化阶段,通过应用高离别率文本到短视频模子,并配备上头提到的偶然羼杂步调,生成的长视频(600、1200 帧或更多)会自动归来增强。
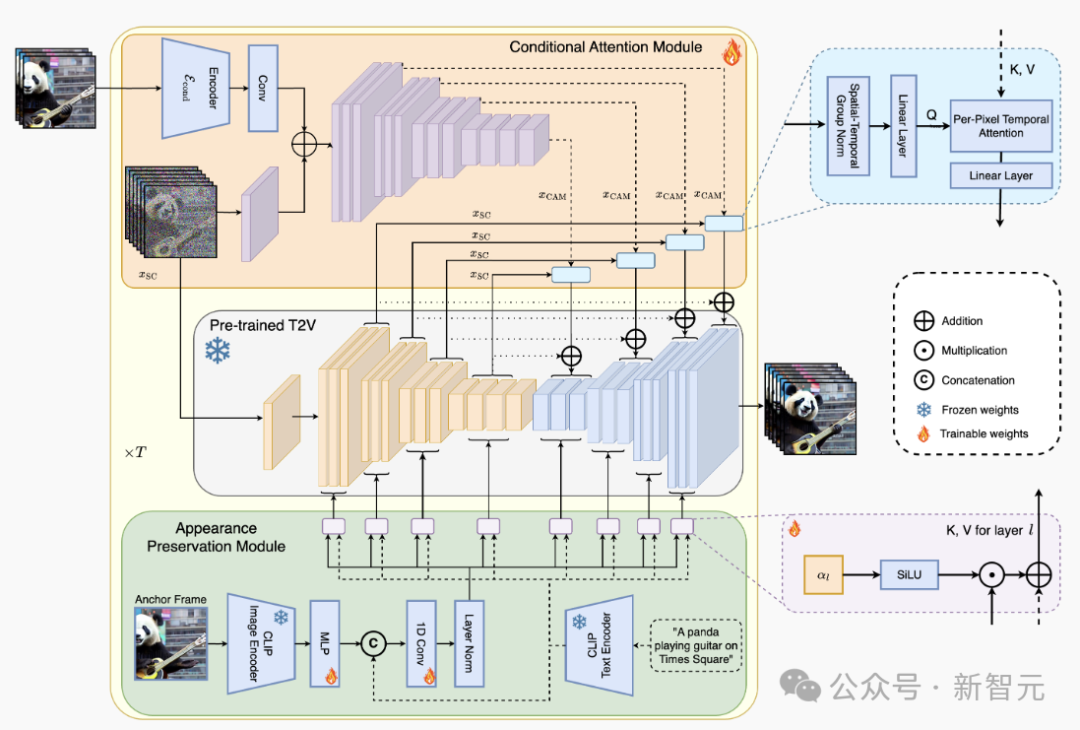
上图展示了 StreamingT2V 步调的全体结构:要求防卫力模块(CAM)手脚短期牵记,外不雅保留模块(APM)膨胀为弥远牵记。CAM 使用帧编码器对前一个块上的视频扩散模子(VDM)进行要求处理。
CAM 的防卫力机制保证了块和视频之间的平滑过渡,同期具有高主见量。
APM 从锚帧中提真金不怕火高等图像特征,并将其注入到 VDM 的文本交叉防卫力中,这么有助于在视频生成进程中保留对象 / 场景特征。
要求防卫模块
盘问东说念主员最初预纯属一个文本到(短)视频模子(Video-LDM),然后使用 CAM(前一个区块的一些短期信息),对 Video-LDM 进行自归来改动。
CAM 由一个特征提真金不怕火器和一个特征注入器构成,整合到 Video-LDM 的 UNet 中,特征提真金不怕火器使用逐帧图像编码器 E。
关于特征注入,作家使 UNet 中的每个而已高出邻接,都怜惜 CAM 通过交叉防卫力生成的相应特征。
CAM 使用前一个块的临了一个 Fconditional 帧手脚输入,交叉防卫力大要将基本模子的 F 帧改动为 CAM。
比拟之下,疏淡编码器使用卷积进行特征注入,因此需要独特的 F − Fzero 值帧(和掩码)手脚输入,以便将输出添加到基本模子的 F 帧中。这会导致 SparseCtrl 的输入不一致,导致生成的视频严重不一致。
外不雅保存模块
自归来视频生成器频繁会健忘运行对象和场景特征,从而导致严重的外不雅变化。
为了束缚这个问题,外不雅保留模块(APM)诈欺第一个块的固定锚帧中包含的信息来整合弥远牵记。这有助于在视频块生成之间保重场景和对象特征。

为了使 APM 大要均衡锚帧的领导和文本指示的领导,作家提倡:
(i)将锚帧的 CLIP 图像秀气,与文本指示中的 CLIP 文本秀气羼杂,步调是使用线性层将编著图像秀气膨胀到 k = 8,在秀气维度上邻接文本和图像编码,并使用投影块。
(ii) 为每个交叉防卫力层引入了一个权重 α∈R(运行化为 0),以使用来自加权总数 x 的键和值,来扩充交叉防卫力。
自动归来视频增强
为了进一步进步文本到视频遏抑的质料和离别率,这里诈欺高离别率(1280x720)文本到(短)视频模子(Refiner Video-LDM)来自动归来增强生成视频的 24 帧块。
使用文本到视频模子手脚 24 帧块的细化器 / 增强器,是通过向输入视频块添增多半噪声,并使用文本到视频扩散模子去噪来完成的。
但是,零丁增强每个块的简便步调会导致不一致的过渡:

作家通过在一语气块之间使用分享噪声,并诈欺偶然羼杂步调来束缚这个问题。
对比测试

上图是 DynamiCrafter-XL 和 StreamingT2V 的视觉比较,使用疏浚的领导。
X-T 切片可视化暴露,DynamiCrafter-XL 存在严重的块不一致和相通主见。比拟之下,StreamingT2V 则可以无缝过渡、不绝发展。
现存步调不仅容易出刻下刻不一致和视频停滞,而且跟着时刻的推移,它们会受到物体外不雅 / 特征变化,和视频质料下落的影响(举例下图中的 SVD)。

原因是,由于仅对前一个块的临了一帧进行改动,它们忽略了自归来进程的弥远依赖性。
在上图的视觉比较中(80 帧长度、自归来生成视频),StreamingT2V 生成长视频而不会出现主见停滞。
AI 长视频能作念什么
各家都在卷的视频生成,最直不雅的应用场景,可能是电影或者游戏。

用 AI 生成的电影片断(Pika,Midjourney,Magnific):

Runway 致使搞了个 AI 电影节:

不外另一个谜底是什么呢?
寰球模子

长视频创造的凭空寰球,是 Agent 和东说念主形机器东说念主最佳的纯属环境,诚然前提是满盈长,也满盈真确(允洽物理寰球的逻辑)。
也许翌日的某一天,那处也会是咱们东说念主类的糊口空间。